
以 USDT 聞名的穩定幣公司 Tether,剛剛發布了一款醫療AI模型,它小巧到可以放進口袋,且效能可能超越比其大數十倍的競爭對手。QVAC MedPsy 今日由 Tether 的 AI 研究小組推出,作為一類新型醫療語言模型,旨在智慧型手機、穿戴式裝置和邊緣裝置上運行——無需雲端服務。
最引人注目的是:一個僅17億參數的小型模型,儘管體積不及 Google 的 MedGemma-4B 的一半,卻能在醫療基準測試中擊敗它。在 HealthBench Hard (OpenAI 用於評估 AI 在真實、多輪臨床對話中表現的基準,由262位醫師評分) 上,Tether 表示其17億參數的模型得分超越了 MedGemma-27B,後者是一個規模近十六倍大的模型。
參數是模型在訓練過程中學習到的所有配置和數值。理論上,參數越多,模型應該越好。
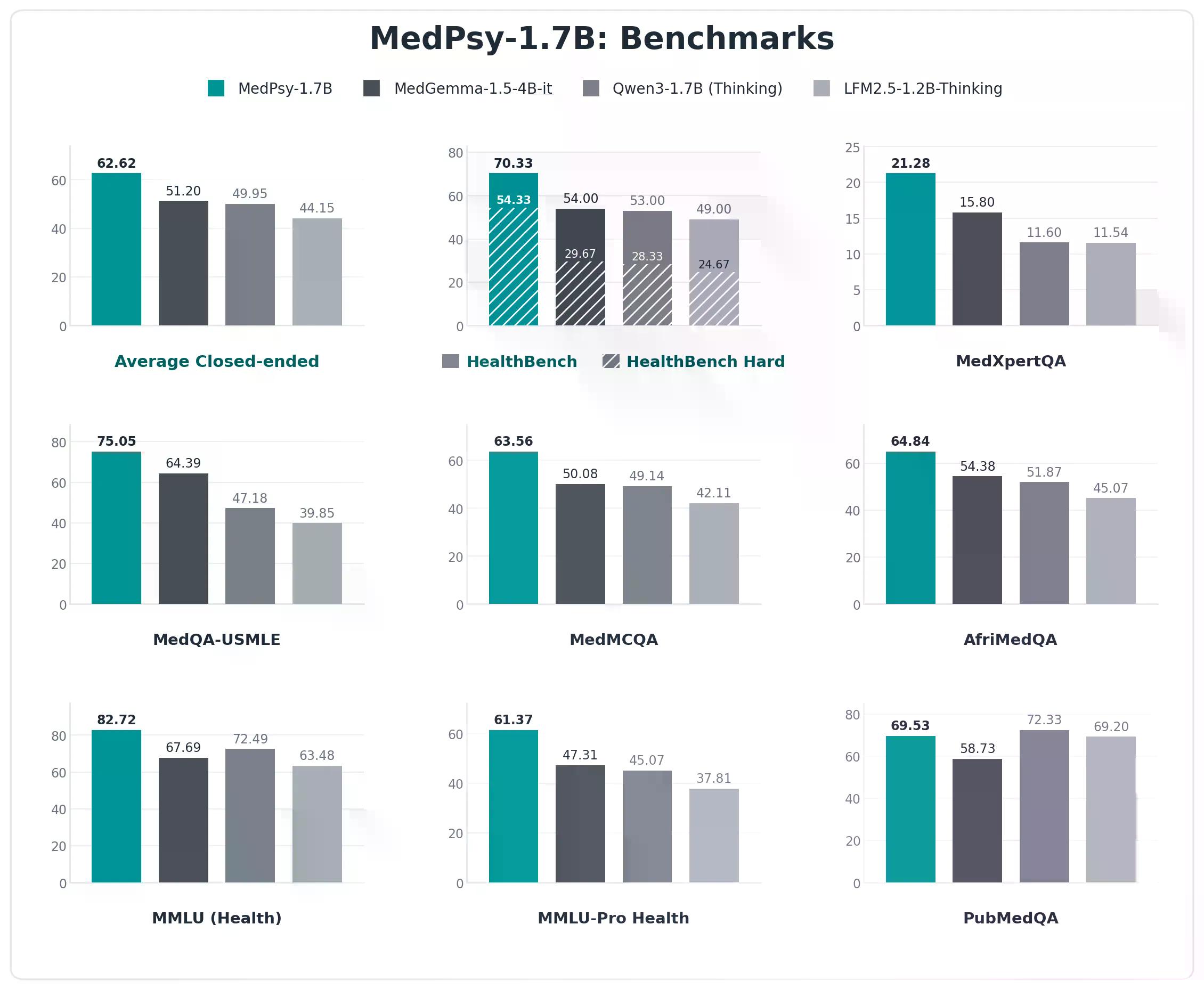
該測試套件涵蓋了 MedQA-USMLE,它使用美國醫師執照考試風格的問題,以準確度百分比來衡量臨床知識;直至 AfriMedQA,它專門測試模型在服務不足的非洲醫療環境中的表現。
Tether 執行長 Paolo Ardoino 將這些進步歸因於效率而非規模。他在一份聲明中表示:「對於 QVAC MedPsy,我們的重點是提高模型層面的效率,而不是擴大規模。我們的40億參數模型超越了體積近七倍的模型所取得的成果,同時每次回應使用的詞元量減少了三倍。」
這種詞元效率是另一個焦點。這個40億參數模型每次回應平均約909個詞元,而同類系統則為2,953個——減少了3.2倍。更少的詞元意味著更低的運算成本、更快的響應,以及最關鍵的,無需雲端後端即可在本地運行。
Ardoino 表示:「你可以在資料已經存在的環境中,例如醫院系統內部或裝置上運行醫療推理,而無需透過雲端傳輸敏感資訊或等待外部處理。」
這些模型以量化 GGUF 檔案形式發布——17億參數模型為1.2 GB,40億參數模型為2.6 GB——其壓縮版本在保持大部分基準效能的同時,也能適應標準消費級硬體。這意味著醫院系統、鄉村診所或個人臨床醫生可以完全在裝置上運行該模型,使病患記錄遠離第三方雲端基礎設施,並避免 HIPAA(健康保險流通與責任法案)風險。
隱私方面的優勢可能對某些人來說是一大亮點,但即使以目前的標準來看,使用AI提供醫療意見也遠非理想。牛津大學二月發表的一項研究發現,大型語言模型(LLMs)經常給出危險的醫療建議,存在錯誤答案、混亂的指導以及對細微症狀處理不當的問題。研究人員並未完全否定這項技術,但主張AI的角色應是「秘書,而非醫師」。合規性問題使其更加複雜:目前大多數醫療AI都會透過雲端伺服器傳輸病患資料,這使得醫師每次輸入查詢時都會產生 HIPAA 風險。
這次發布符合 Tether 過去一年的發展模式。上個月,它推出了 QVAC SDK,這是一個用於在 iOS、Android、Windows 和 Linux 上構建本地、離線 AI 應用程式的開源工具包。在此之前,它還推出了 QVAC Health,這是一款將生物識別資料完全保留在裝置上的消費者健康應用程式。MedPsy 是第一個專門為臨床推理訓練的 QVAC 模型。
根據 Tether 自己的公告,醫療AI市場目前約為360億美元,預計到2033年將超過5000億美元。模型和 GGUF 權重現已在 qvac.tether.io/models 提供。