
大多數人認識小米是中國手機品牌。一個生產廉價電動滑板車和空氣清淨機的公司。你不會期待它在某個週一早上打破一項主要的 AI 推論速度紀錄。
然而,小米剛剛發布了 MiMo-V2.5-Pro-UltraSpeed,這是其兆級參數旗艦模型的一個服務模式,其速度超過每秒 1,000 個 token——在演示中峰值接近 1,200。
參數是定義模型思維方式的內部數值權重——參數越多,模型能識別的模式就越複雜。Token 是模型讀寫的文字區塊,平均每個約為四分之三個單詞。
小米在單一 8 顆 GPU 商用節點上實現了這一點。標準硬體,無客製化晶片。這改變了誰能真正將這種速度投入生產的計算方式。
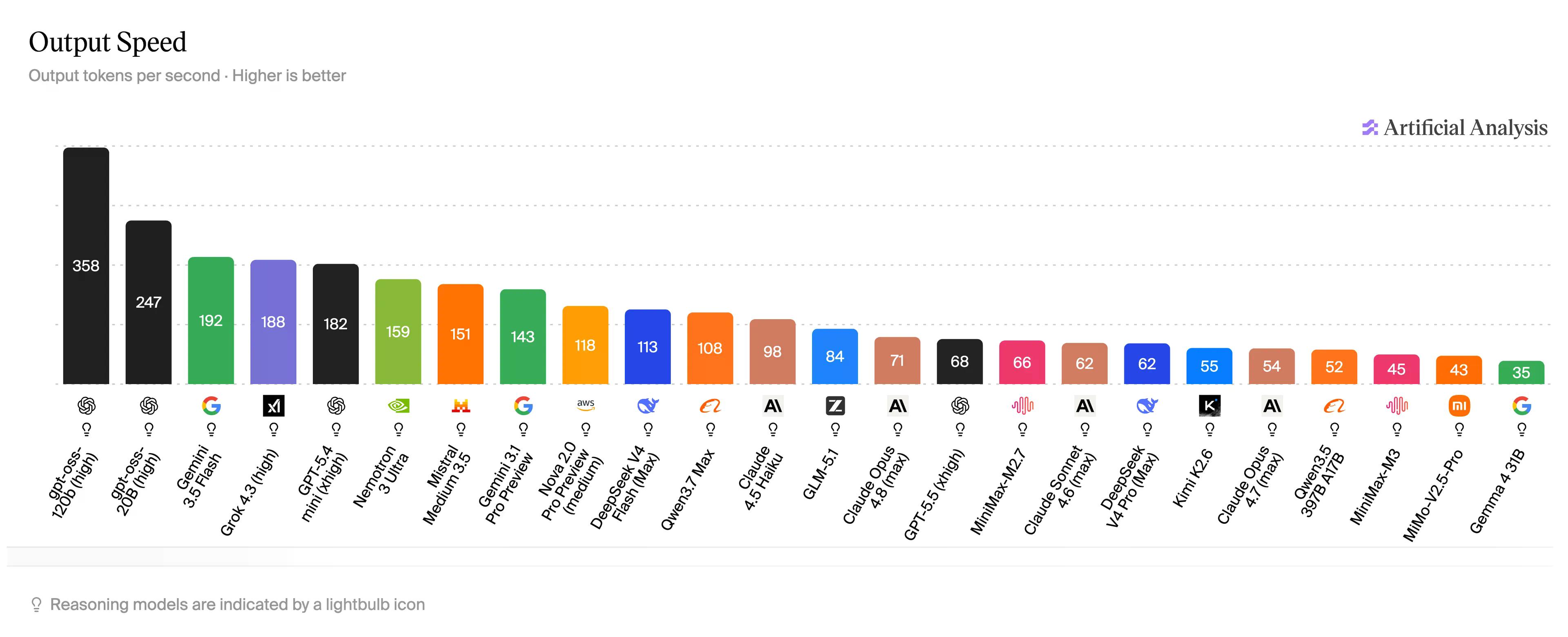
用白話來說:根據 Artificial Analysis 的數據,GPT-5.5——大多數 ChatGPT 用戶實際使用的模型——約為 68。Claude Opus 4.6 約為 71,較低階的模型 Haiku 則達到每秒 98 個 token。Gemini Flash 達到每秒 192 個 token。MiMo-V2.5-Pro-UltraSpeed 則能達到 1,000,而且該模型在程式編碼基準測試中與 Opus 旗鼓相當。
Cerebras 和 Groq 都圍繞這個問題建立起了整個業務。Cerebras 設計了一款晶圓級晶片,大小如同餐盤,內建 44GB 的晶片內存,以消除減緩 GPU 推論速度的頻寬瓶頸。它在 Meta 的 Llama 3.1 405B 上達到了每秒 969 個 token——這令人印象深刻,但那是一個 4050 億參數的模型,不到 MiMo-V2.5-Pro 模型大小的一半。Groq 的客製化語言處理單元 (LPU) 架構,根據模型的不同,最高可達每秒 300–750 個 token。
這兩者都無法在今晚從 AWS 租賃到的硬體上運行。
小米僅透過軟體就做到了,在通用型 GPU 上——結合了模型級別的技巧和一個專為推論而設計的引擎 TileRT。
有兩種技術促成了這次的速度提升。第一種技術稱為 FP4 量化:小米沒有以完整的 8 位元或 16 位元數值精度運行模型,而是將構成萬億參數大部分的專家層縮小到 4 位元。記憶體佔用量下降,頻寬壓力減輕,速度隨之提升。通常這種做法會伴隨輕微的品質下降。小米的解決方案是精準的:只有專家層被壓縮,其他部分保持完整精度。透過這種方法,品質損失被描述為接近於零。
第二種是 DFlash 推測性解碼。正常的推測性解碼是讓一個小型草稿模型預測接下來的幾個 token,然後由大型模型平行驗證它們。DFlash 完全跳過循序草稿——它在單次前向傳遞中填充整個遮罩位置區塊。在程式編碼任務中,大型模型在每個驗證輪次中平均接受 8 個提議 token 中的 6.3 個。這表示一次確認了六個 token,而非一個。
TileRT 將這些技術整合在一起。它使整個計算管線持續駐留在 GPU 內部——沒有單個運算子啟動的開銷,也沒有執行間隙。
小米將這種方法稱為「極致的模型與系統協同設計」,這個詞是準確的:單獨任何一項技術都無法達到每秒 1,000 個 token,但所有方法的協同作用則可以。
MiMo-V2.5-Pro 是一個頂尖模型。我們在四月報導了 V2.5 Pro 的發布——它在大多數程式編碼基準測試中與 Claude Opus 旗鼓相當,每百萬 token 的輸入成本約為 0.43 美元,輸出成本約為 0.87 美元。而 Opus 每百萬 token 的輸入成本為 5 美元,輸出成本為 25 美元。
UltraSpeed 加速的是精確的 MiMo V2.5 Pro 模型,而非簡化版。
足夠快的推論速度改變了模型的使用方式。您可以平行運行數十條推理路徑,而不是等待一個答案。詐欺偵測、交易訊號生成、即時代理迴圈——所有這些都存在硬性延遲限制,每秒 60 個 token 無法滿足。而每秒 1,000 個 token 則可以。
小米將這項速度服務定價為標準 MiMo-V2.5-Pro 費率的 3 倍,以提供約 10 倍的輸出。API 試用將於 6 月 9 日至 23 日開放,採申請制,企業和專業開發者優先。FP4-DFlash 檢查點已在 Hugging Face 上開源,供社群測試。
