
中國科技公司美團於 6 月 30 日正式發布了 LongCat-2.0,證實這款開源許可、擁有 1.6 兆參數的專家混合(mixture-of-experts)AI 模型,正是過去兩個月在 OpenRouter 上以「貓頭鷹阿爾法」(Owl Alpha)之名匿名運行的系統。
參數是模型在訓練期間可以處理的總撥號數。該模型每個代幣(AI 模型處理的最小資料單位)啟動約 480 億個參數,這個數字會根據查詢的複雜程度在 330 億到 560 億之間波動。
隱秘運行階段取得了成效。在美團公開之前,該模型已在 Hermes Agent 工作區中位居第一,在 Claude Code 上排名第二,並在 OpenClaw 的所有部署中排名第三,所有排名均根據每月呼叫量計算。
這是首個完全基於中國國產 ASIC 進行端到端訓練和部署的兆級參數模型,而非僅在其他地方訓練後再用於國產硬體。相比之下,DeepSeek 的 V4-Pro 僅使用華為晶片進行推論,而其預訓練則運行在 Nvidia 硬體上。
美團表示,這次預訓練運行在超過 5 萬個國產加速器組成的叢集上,處理了超過 35 兆個代幣,並以「無回滾或不可恢復的損失峰值」收尾。這項穩定性聲明至關重要,因為大型訓練在未經證實的硬體堆疊上經常中途失敗,而且中國似乎正在減少對美國硬體的依賴來訓練其模型。
價格才是 LongCat-2.0 的真正亮點。標準 API 存取費用為每百萬輸入代幣 0.75 美元,每百萬輸出代幣 2.95 美元;在目前的促銷期間,更降至 0.30 美元/1.20 美元,且快取上下文讀取免費。這遠低於 GPT-5.5 的每百萬代幣 5 美元/30 美元,以及 Claude Sonnet 5 的入門價 2 美元/10 美元,並且與 DeepSeek V4-Pro 的永久定價 0.435 美元/0.87 美元和小米 MiMo-V2.5 Pro 在五月降價後的價格相同。
美團還提供了代幣方案,對於程式設計師和高用量用戶來說,這讓價格更加便宜,提供 10 億代幣的套裝約為 60 美元。
我們親自對 LongCat-2.0 進行了快速的遊戲建構測試。它完成了任務,並且經過幾輪迭代後,輸出結果表現相當不錯。其表現明顯落後於 Claude Fable 和 Opus 4.8,較接近 Sonnet 4.6 的水平,但考慮到這些價格,其性價比確實難以反駁。
它讓敵人從不同角度湧現,攝影機自動鎖定最近的敵人。然而,該模型的邏輯並未考慮到當難度增加時,敵人數量增多的情況。在更高的速度下,目標切換邏輯變得不穩定;在打字提示中,焦點會跳轉到更近的敵人,使得遊戲體驗令人沮喪。
這在「情緒化編碼」(vibe coding)環節中很常見,模型通常不會預見到決策的許多邏輯後果,而是只專注於根據用戶的提示字面意義提供結果。
這也是為什麼廉價模型總是一個好選擇,因為它讓用戶有更多機會迭代改進每個結果,直到最終產品符合預期。
如果沒有進一步互動,乍看之下,在我們的快速程式碼測試中,整體品質介於 DeepSeek v4 Flash 和 DeepSeek v4 Pro 之間。
您可以在我們的 itch.io 網站上查看結果。
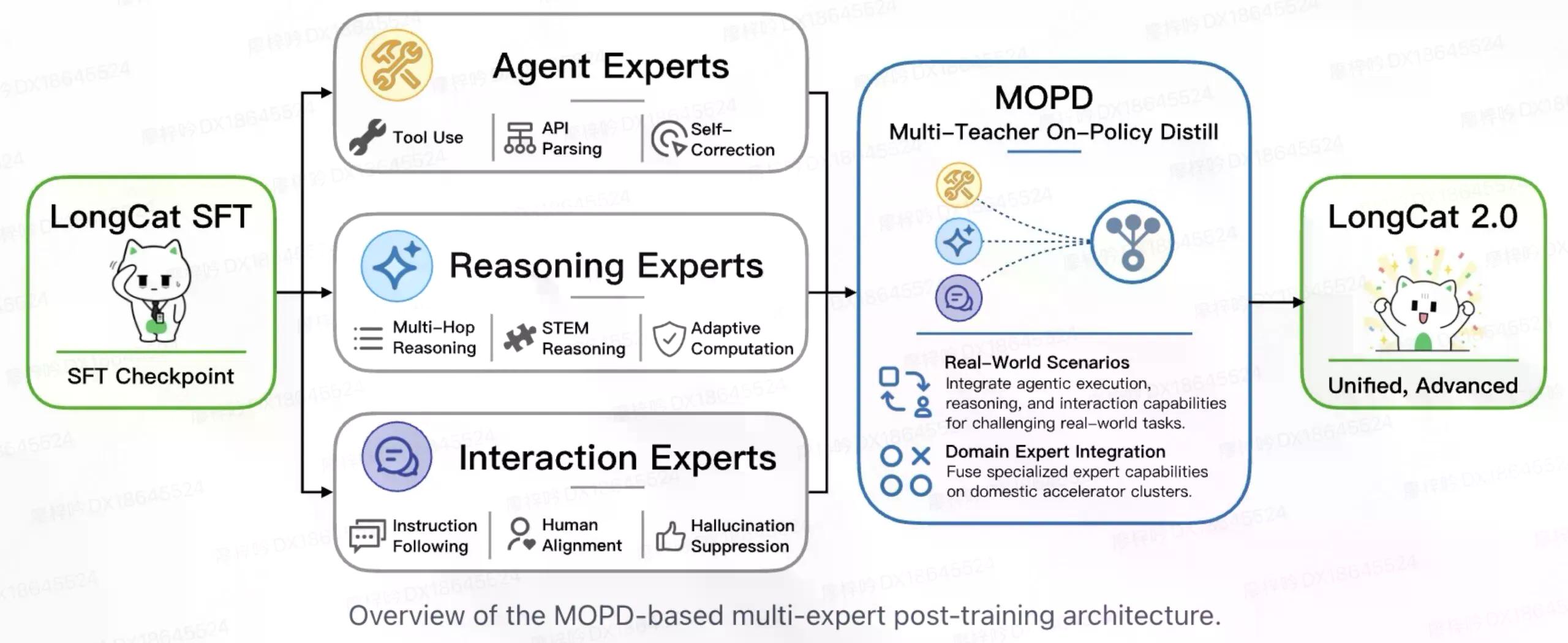
LongCat-2.0 採用了多種技術,使其模型更快速、更強大,而無需大幅增加其規模。
其注意力機制基於 DeepSeek 的設計,僅專注於極長對話中最相關的部分,而非平均處理所有內容,有助於其更快回應。
此外,一種新的 N-gram 嵌入系統(一種幫助理解單詞或子詞組合的方式)賦予模型對單詞和短語更豐富的理解——約 100 倍更多的可能表示——而無需增加更多的 AI 組件。這基本上是在教導 AI 識別常用短語,而非僅僅是個別單詞。與其將「New」、「York」和「City」視為三個獨立的部分,它也能將「New York City」視為一個有意義的單一概念。這讓模型對語言有更豐富的理解,而不會顯著增加其規模。
訓練結束後,美團還結合了三個專門系統:一個專注於工具使用(Agent),一個專注於問題解決(Reasoning),以及一個專注於對話(Interaction)。然後,一個路由機制會決定哪種專家組合應該處理每個請求,這就像為合適的任務分配合適的團隊一樣。
在 SWE-bench Pro 上(一個衡量模型解決從生產程式碼庫中提取的真實 GitHub 問題頻率的基準測試),LongCat-2.0 達到 59.5 分,領先於 GPT-5.5 的 58.6 分和 Gemini 3.1 Pro 的 54.2 分,但仍落後於 Claude Opus 4.7 和 4.8。在 FORTE 上(一個在 45 分鐘時限內,評估代理在 15 種職業中日常辦公任務的表現的基準測試),它獲得了 73.2 分,與 Claude Opus 4.6 持平,但落後於 GPT-5.5 的 77.8 分。
Introducing LongCat-2.0 🐱
1.6T parameters · MoE with ~48B active · 1M context
The full model behind Owl Alpha on @OpenRouter — now available.Built for agentic coding from the ground up:
◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
◆… pic.twitter.com/zum2SdZ0Z2— Meituan LongCat (@Meituan_LongCat) June 30, 2026
對於預算有限的編碼代理建構團隊,或任何進行大量、倉庫級工作且可利用免費上下文快取讀取優勢的人來說,LongCat-2.0 提供了最明顯的優勢。該模型目前可透過美團與 OpenAI 和 Anthropic 相容的 API 端點,或透過已整合它的代理框架,如 Hermes、Claude Code 和 OpenClaw 存取。
目前需要自行託管的用戶運氣不佳。GitHub 和 Hugging Face 儲存庫都仍顯示「模型權重即將推出」,但美團尚未確定文件發布的日期。
