
Z.ai 於 6 月 16 日發布了 GLM-5.2,承諾提供頂級效能,超越其已有的進階模型 GLM 5.1。
這家總部位於北京的實驗室自 2025 年 1 月以來一直名列美國實體清單,似乎正從外界對美國 AI 策略日益增長的擔憂中獲益。過去一週,Anthropic Fable 的禁令以及這款新模型的發布,幫助 zAI 的股價飆升了 90%,創下歷史新高。
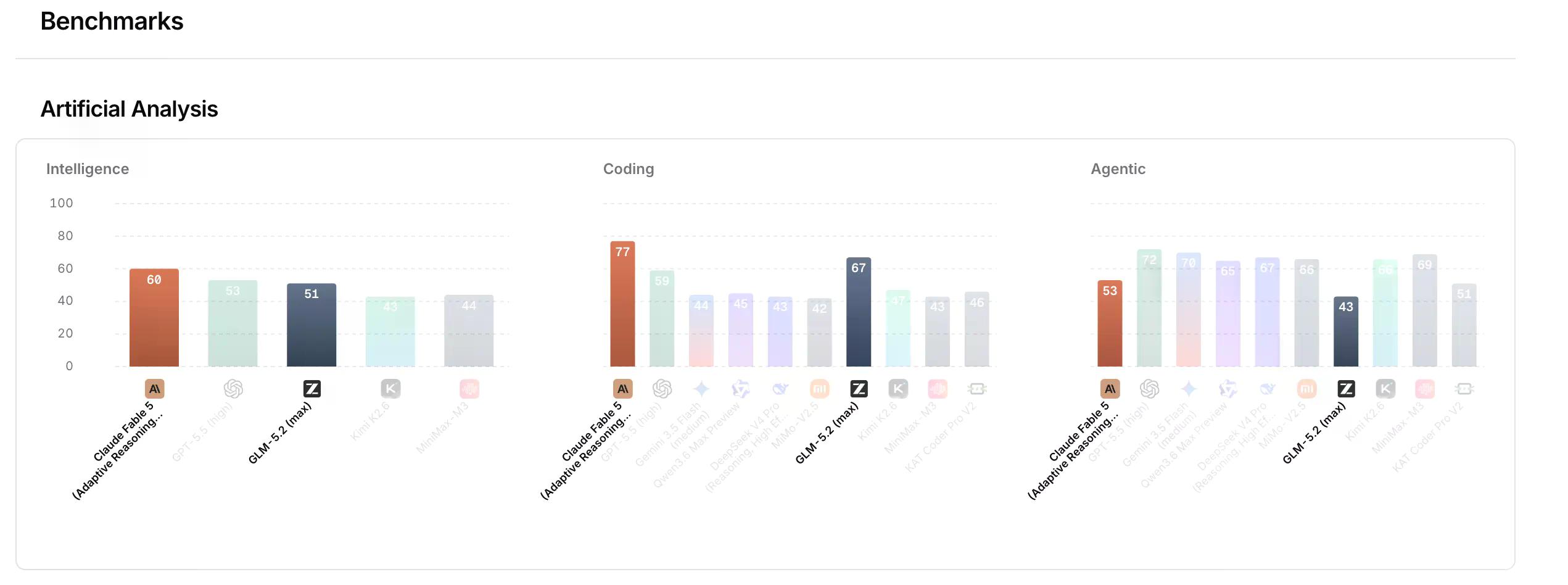
GLM 5.2 有數據支持其宣傳。
在 FrontierSWE(一個衡量 AI 代理是否能完成數小時開放式技術專案的基準測試,涵蓋系統優化、大規模程式碼建構和應用機器學習研究,以支配率計分)上,GLM-5.2 獲得 74.4 分,而 Claude Opus 4.8 則為 75.1 分。它以 72.6 分險勝 GPT-5.5。在 SWE-bench Pro(測試自主解決真實 GitHub 問題的通過率)上,GLM-5.2 獲得 62.1 分,而 GPT-5.5 則為 58.6 分,大幅超越其前身 GLM-5.1 的 58.4 分。
品質上的躍升使其成為至今在人工分析智慧指數 (Artificial Analysis Intelligence Index) 中最好的開源模型,該指數匯總了 9 項不同分數來評估 AI 模型的整體品質。OpenRouter 的基準測試將其歸類為與目前被禁用的 Claude Fable 5 同等級。
實現這一壯舉所使用的硬體是故事中另一個有趣的環節。GLM-5.2 在華為昇騰晶片上進行訓練,整個過程中沒有涉及任何 Nvidia 硬體。Stability AI 的創辦人 Emad Mostaque 估計總訓練成本約為 2500 萬美元,其中 80% 用於後續訓練,這與其競爭對手相比,成本極其低廉。
正如 Decrypt 今年稍早報導,Z.ai 已經在華為昇騰 Atlas 伺服器上訓練影像模型,沒有使用任何美國晶片。GLM-5.2 進一步利用了該基礎設施—這是一個擁有 7440 億參數的專家混合模型,具有真實的 100 萬 token 上下文視窗,是 GLM-5.1 20 萬 token 限制的五倍,並且採用 MIT 授權,這意味著任何政府指令都無法關閉其存取開關。
Tokens 是模型可以讀取和生成的文本片段,而 Parameters 則是決定模型如何處理資訊和生成回應的內部設定和數值數量。
對於開發者而言,上下文視窗是操作上的轉變。過去需要分塊處理的整個程式碼庫導航、多檔案重構以及冗長的代理管道,現在可以透過單次呼叫工作流程完成。API 定價為每百萬輸入 token 1.40 美元,每百萬輸出 token 4.40 美元,相較之下 Claude Opus 4.8 的輸入為 5 美元,輸出為 25 美元。Coding Plan 每月約 18 美元起,可直接在 Claude Code、Cline、Kilo Code 和大多數流行的代理環境中使用。
本地部署在技術上也是可行的。Unsloth AI 推出了 2 位元 GGUF 量化版本,將模型從 1.51TB 壓縮至 238GB,同時保持約 82% 的準確性。
不過別高興得太早。這仍然意味著它需要 256GB 的統一記憶體,或者相應的 RAM/VRAM 組合——例如一台配置最高的 M4 Ultra Mac Studio,或者一台配備中階 GPU 和 256GB 系統記憶體並啟用專家混合卸載的工作站。這仍然是一筆不小的開銷,但至少如果你真的想,它是可以購買並在家中運行的。
我們進行了一項快速測試,要求 GLM-5.2 建立我們的標準遊戲,結合打字機制與射擊玩法。使用者介面並不是最美觀的——其他模型生成了更精緻的介面,但體驗卻是最豐富多樣的:不同波次的場景、不斷變化的敵人類型,以及在遊戲後期出現的頭目。
在零樣本設置下,它為相同任務生成的遊戲狀態比我們測試過的其他任何模型都更加多樣化。
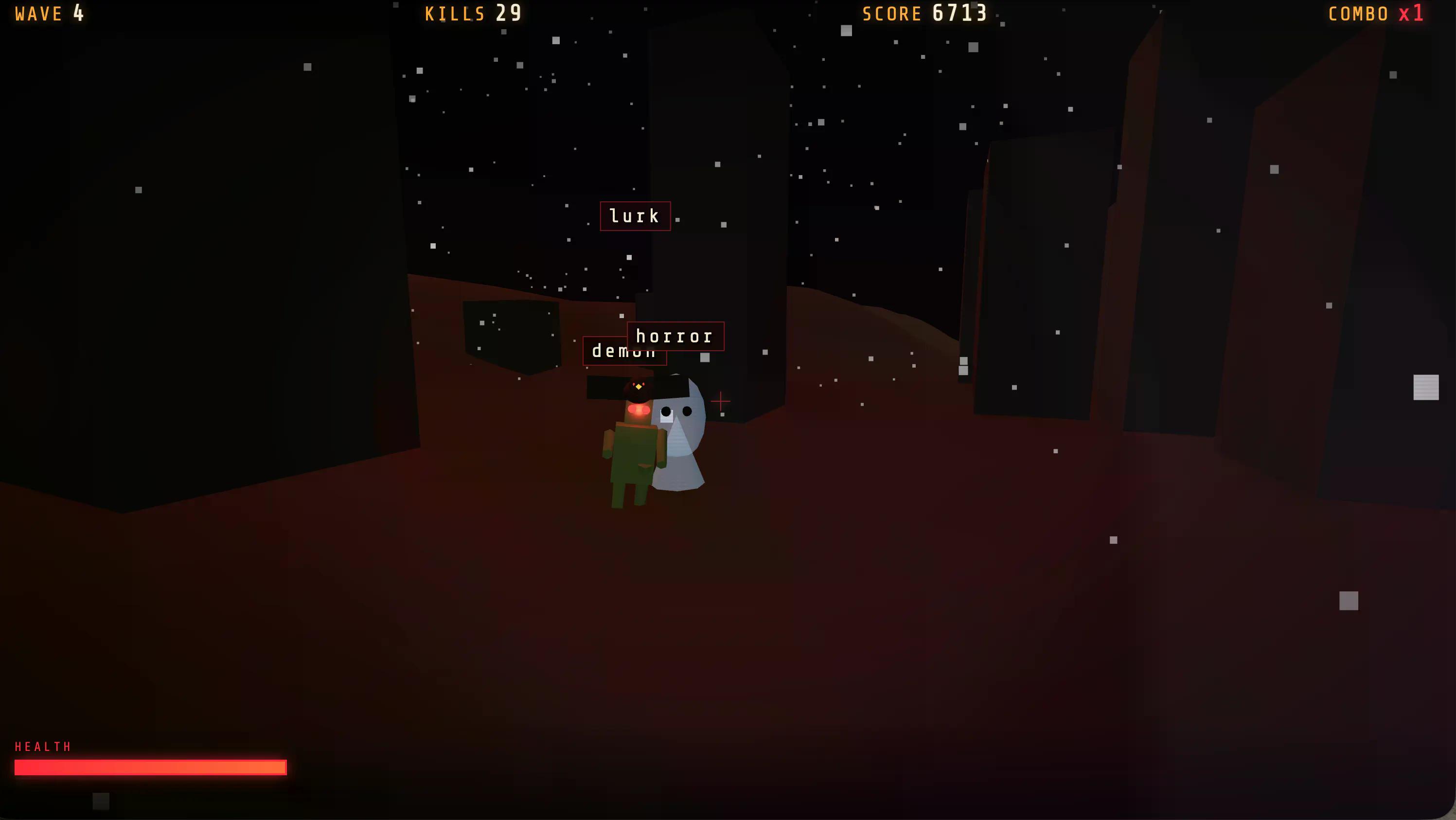
如果你想玩,它已在我們的 Itch.io 個人檔案上線。
這種變異性指出了 GLM-5.2 最具經濟效益的地方。對於多樣本生成工作流程和代理管道,如果輸出多樣性比精緻度更重要,那麼以開源定價水準來看,其數學上的優勢是難以辯駁的。對於最艱鉅的持續性任務——例如 SWE-Marathon,它得分為 13.0,而 Opus 4.8 為 26.0——與封閉式前沿模型之間的差距仍然存在,並且有 13 分之寬。
開源權重已在 HuggingFace 上以 MIT 授權發布。量化權重也已在 HuggingFace 上提供。GLM Coding Plan 訂閱者現在可以使用模型字串 GLM-5.2 進行切換,它也可以在 z.AI 上免費測試,但帶有一些使用限制。
