
Karamihan sa mga tao ay kilala ang Xiaomi bilang Chinese brand ng telepono. Ang gumagawa ng murang electric scooter at air purifier. Hindi ito ang kumpanyang inaasahan mong makakabasag ng isang malaking record sa bilis ng AI inference sa isang Lunes ng umaga.
Ngunit. Inilabas lamang ng Xiaomi ang MiMo-V2.5-Pro-UltraSpeed, isang serving mode para sa flagship nitong may trilyong parameter na nakakaabot ng higit sa 1,000 token kada segundo—na umaabot sa halos 1,200 sa mga demo.
Ang mga parameter ay ang panloob na numerical weights na nagtatakda kung paano mag-isip ang isang modelo—mas marami ka nito, mas kumplikadong pattern ang makikilala nito. Ang mga token ay ang mga bahagi ng teksto na binabasa at isinusulat ng modelo, humigit-kumulang tatlong-kapat ng isang salita bawat isa sa average.
Nagawa ito ng Xiaomi gamit ang isang karaniwang 8-GPU commodity node. Karaniwang hardware, walang custom na chips. Binabago nito ang kalkulasyon kung sino ang talagang makakapag-deploy ng ganitong uri ng bilis sa produksyon.
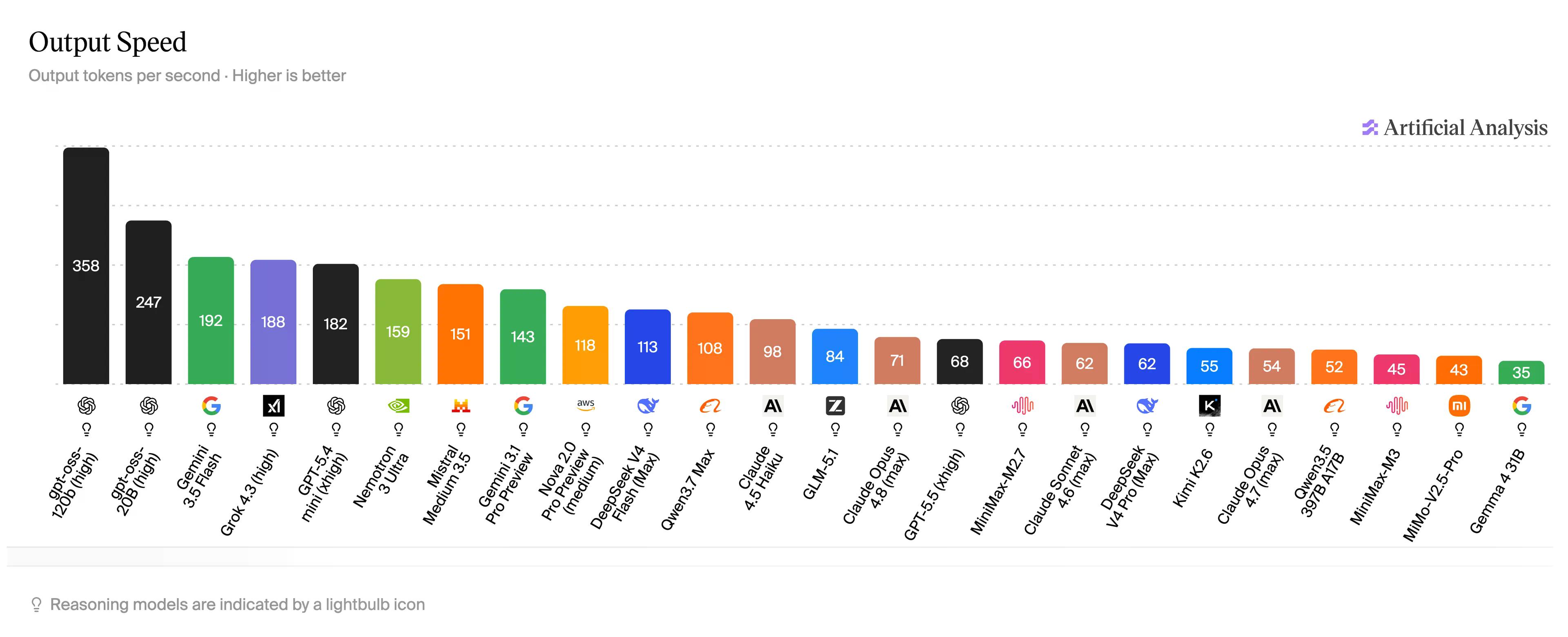
Sa madaling salita: ayon sa Artificial Analysis, ang GPT-5.5—na siyang kinakausap ng karamihan sa mga user ng ChatGPT—ay nasa 68. Ang Claude Opus 4.6 ay nasa humigit-kumulang 71, habang ang mas mababang modelo, ang Haiku, ay umaabot sa 98 token kada segundo. Ang Gemini Flash ay nakakaabot ng 192 token kada segundo. Ang MiMo-V2.5-Pro-UltraSpeed ay nakakagawa ng 1,000, sa isang modelo na tumutugma sa Opus sa mga coding benchmark.
Nagtayo ang Cerebras at Groq ng buong negosyo sa paligid ng problemang ito. Nagdisenyo ang Cerebras ng isang wafer-scale chip na kasinglaki ng plato, na may 44GB ng on-chip memory upang alisin ang bandwidth bottleneck na nagpapabagal sa GPU inference. Naabot nito ang 969 token kada segundo sa Llama 3.1 405B ng Meta—kahanga-hanga, ngunit iyan ay isang 405-bilyong-parameter na modelo, mas mababa sa kalahati ng laki ng MiMo-V2.5-Pro. Ang custom na arkitektura ng Language Processing Unit ng Groq ay umaabot sa humigit-kumulang 300–750 token kada segundo depende sa modelo.
Wala sa mga ito ang tumatakbo sa hardware na maaari mong rentahan mula sa AWS ngayong gabi.
Nagawa ito ng Xiaomi sa mga commodity GPU sa pamamagitan lamang ng software—isang kumbinasyon ng mga diskarte sa antas ng modelo at isang inference engine na binuo para sa layunin na tinatawag na TileRT.
Dalawang diskarte ang nagbibigay ng bilis. Ang unang diskarte ay tinatawag na FP4 Quantization: sa halip na patakbuhin ang modelo sa buong 8-bit o 16-bit numerical precision, binabawasan ng Xiaomi ang mga expert layers—na bumubuo sa karamihan ng 1 trilyong parameter—sa 4-bit. Bumababa ang memory footprint, bumababa ang bandwidth pressure, tumataas ang bilis. Ang karaniwang problema ay isang maliit na pagbaba sa kalidad. Ang solusyon ng Xiaomi ay surgical: tanging ang mga expert layer lamang ang kinokompres, ang lahat ng iba pa ay nananatili sa full precision. Sa diskarteng ito, ang pagkawala ng kalidad ay inilalarawan bilang halos zero.
Ang pangalawa ay DFlash speculative decoding. Sa normal na speculative decoding, mayroong isang maliit na draft model na humuhula sa susunod na ilang token, pagkatapos ay bini-verify ng malaking modelo ang mga ito nang sabay-sabay. Nilalaktawan ng DFlash ang sequential drafting nang buo—pinupuno nito ang isang buong bloke ng mga masked na posisyon sa isang solong forward pass. Sa mga coding task, tinatanggap ng malaking modelo ang average na 6.3 sa 8 ipinapanukalang token bawat verification round. Ibig sabihin, anim na token ang nakumpirma sa isang hakbang sa halip na isa.
Pinagsasama-sama ito ng TileRT. Pinananatili nito ang buong compute pipeline na patuloy na naninirahan sa loob ng GPU—walang per-operator launch overhead, walang execution gaps.
Tinawag ng Xiaomi ang diskarteng ito na "extreme model-system codesign," at tumpak ang parirala: Walang diskarte na mag-isa ang makakaabot ng 1,000 token kada segundo, ngunit ang synergy sa pagitan ng lahat ng mga diskarte ay ginagawa ito.
Ang MiMo-V2.5-Pro ay isang frontier-level na modelo. Sinakop namin ang paglulunsad ng V2.5 Pro noong Abril—ito ay tumutugma sa Claude Opus sa karamihan ng mga coding benchmark at tumatakbo sa humigit-kumulang $0.43 input / $0.87 output kada milyong token. Ang Opus ay nagkakahalaga ng $5 input / $25 output kada milyong token.
Pinapabilis ng UltraSpeed ang eksaktong modelo ng MiMo V2.5 Pro, hindi isang pinababang bersyon.
Ang sapat na bilis ng inference ay nagbabago kung paano mo magagamit ang isang modelo. Maaari kang magpatakbo ng dose-dosenang reasoning paths nang sabay-sabay sa halip na maghintay para sa isang sagot. Ang pagtukoy ng pandaraya, pagbuo ng trading signal, real-time agent loops—lahat ng ito ay may mahirap na latency constraints na hindi kayang matugunan ng 60 token kada segundo. Sa bilis na 1,000 token kada segundo, kaya nila.
Pinapresyuhan ng Xiaomi ang bilis sa 3 beses ang karaniwang rate ng MiMo-V2.5-Pro para sa humigit-kumulang 10 beses ang output. Ang pagsubok sa API ay tatakbo mula Hunyo 9–23, nakabatay sa aplikasyon, na may prayoridad na ibibigay sa mga enterprise at propesyonal na developer. Ang FP4-DFlash checkpoint ay open-sourced na sa Hugging Face para sa pagsubok ng komunidad.
