
Inilunsad ng OpenAI ang GPT-5.5 noong Huwebes, na inilalako ito bilang isang modelo na nakatuon sa agentic na paggamit ng computer. Sumusulat at nagde-debug ito ng code, nagba-browse sa web, nagpupuno ng spreadsheets, at patuloy na gumagawa ng maraming-hakbang na gawain nang hindi kailangan ng tao upang bantayan ang bawat galaw.
Ang paglabas ay unti-unti nang ipinapatupad ngayon sa mga subscriber ng Plus, Pro, Business, at Enterprise sa buong ChatGPT at Codex, ayon sa OpenAI.
“Inilalabas namin ang GPT‑5.5, ang aming pinakamatalino at pinaka-madaling gamiting modelo sa ngayon, at ang susunod na hakbang tungo sa isang bagong paraan ng paggawa ng trabaho sa computer,” sabi ng OpenAI sa isang anunsyo. “Ang mga benepisyo ay partikular na matindi sa agentic coding, paggamit ng computer, gawaing pangkaalaman, at maagang pananaliksik sa siyensya—mga lugar kung saan ang pag-unlad ay nakasalalay sa pangangatwiran sa iba't ibang konteksto at paggawa ng aksyon sa paglipas ng panahon.
Ipinakikilala ang GPT-5.5
Isang bagong klase ng intelligence para sa tunay na trabaho at pagpapagana ng mga ahente, binuo upang maunawaan ang kumplikadong mga layunin, gumamit ng mga tool, suriin ang sariling gawa, at kumpletuhin ang mas maraming gawain. Ito ay nagmamarka ng bagong paraan ng paggawa ng trabaho sa computer.
Ngayon ay available sa ChatGPT at Codex. pic.twitter.com/rPLTk99ZH5
— OpenAI (@OpenAI) April 23, 2026
Ang malaking balita mula sa OpenAI: Ang GPT-5.5 ay kapansin-pansin na mas matalino kaysa sa hinalinhan nito, ang GPT-5.4—at hindi ito mas mabagal. Ang pagtutugma sa per-token latency ng GPT-5.4 sa real-world serving habang nakakakuha ng mas mataas na marka sa mga benchmark ay ang uri ng pagpapabuti sa kahusayan na karaniwang hindi nangyayari. Ang mas malalaking modelo ay kadalasang mas mabagal kapag tumatakbo sa ilalim ng parehong hardware.
Sa Terminal-Bench 2.0, na sumusubok kung gaano kahusay ang isang modelo sa paghawak ng mga kumplikadong command-line workflows na nangangailangan ng pagpaplano at paulit-ulit na paggamit ng tool, nakakuha ang GPT-5.5 ng 82.7%. Ang Claude Opus 4.7 ay nakakuha ng 69.4%, habang ang Gemini 3.1 Pro ay nasa 68.5%. Hindi iyon isang maliit na kalamangan.
Sa GDPval, isang benchmark na sumusubok sa gawaing pangkaalaman sa 44 na tunay na propesyon—mula sa pananalapi hanggang sa legal na pananaliksik hanggang sa pamamahala ng produkto—ang GPT-5.5 ay tumutugma o nakakatalo sa mga propesyonal sa industriya sa 84.9% ng mga paghahambing.
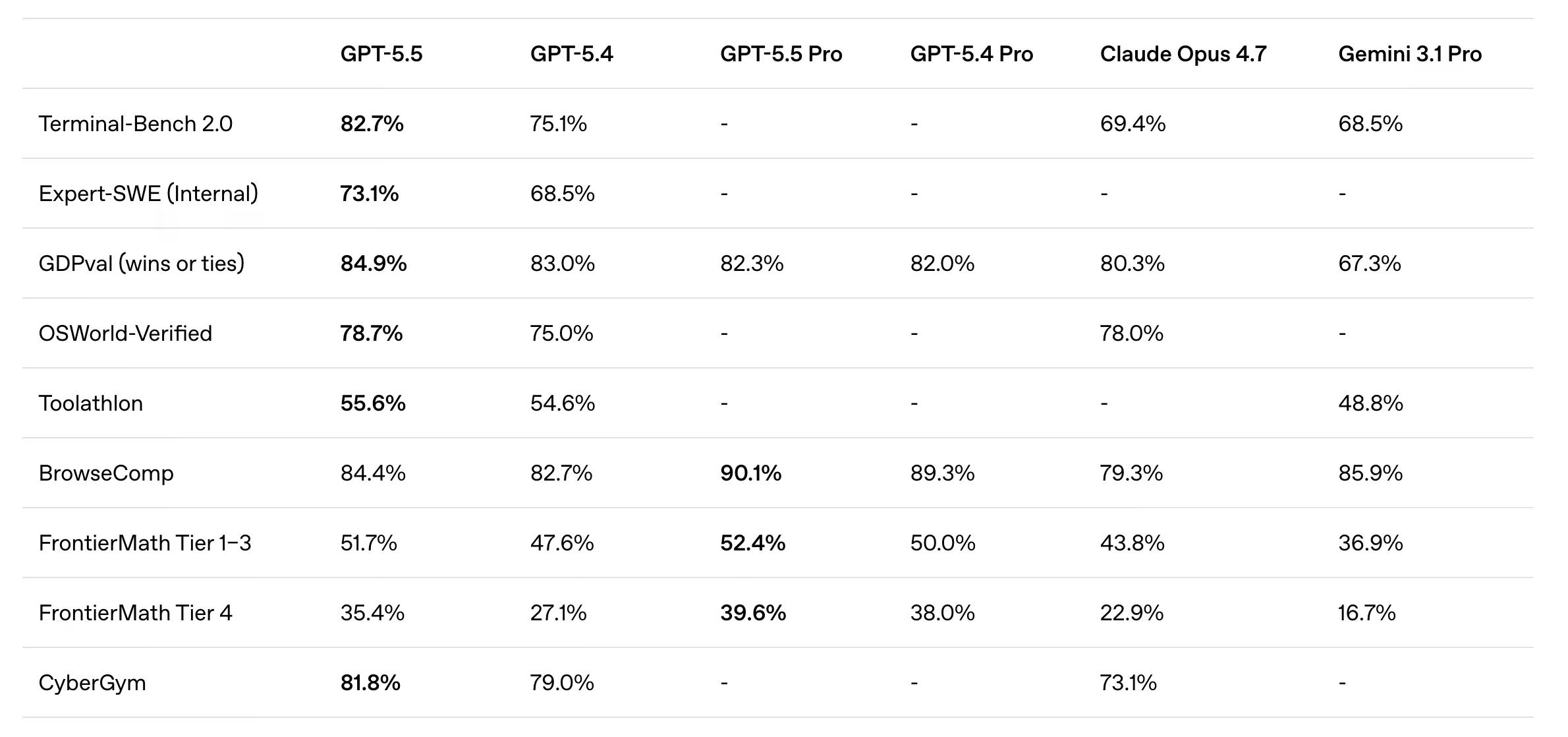
Magaling din itong coder, tulad ng inaasahan. Sa Expert-SWE, isang panloob na benchmark para sa mahahabang gawain sa coding na may median na tinatayang oras ng pagkumpleto ng tao na 20 oras, nalampasan ng GPT-5.5 ang GPT-5.4. Sa SWE-Bench Pro, na nagre-rate ng real-world na paglutas ng isyu sa GitHub, umabot ito sa 58.6%. Mas mataas ang nakuhang marka ng Claude Opus 4.7 sa 64.3%, ngunit sinasabi ng OpenAI na maaaring ito ay dahil “nag-ulat ang Anthropic ng mga senyales ng memorization sa isang subset ng mga problema.”
Ang paglulunsad na ito ay nagaganap sa isang merkado na mabilis na gumagalaw mula nang sumikat ang agentic AI. Dumating ang GPT-5.4 dalawang araw lang matapos ang GPT-5.3, habang ang Xiaomi ay nagmula sa MiMo-V2-Pro patungo sa MiMo 2.5 Pro—na may kumpletong multimodal capabilities—sa loob ng humigit-kumulang limang linggo. Ang pagitan ng GPT-5.4 at GPT-5.5 ay halos pitong linggo. Iyan ang bilis ngayon.
Ngunit makakapagdulot ba ng pagbabago ang modelong ito para sa pang-araw-araw na gumagamit na hindi laging gumagawa ng susunod na malaking proyekto? Kung ikaw ay nasa free tier, hindi: Hindi available ang GPT-5.5 sa mga libreng gumagamit. Kung nagbabayad ka para sa Plus sa $20/buwan, ilulunsad ito ngayon. Sinubukan naming i-test ito sa ilalim ng aming Pro account, ngunit hindi agad available ang modelo.
Ang mas malaking usapin ay marahil ang ginagawa ng GPT-5.5 sa loob ng Codex—ang agentic coding environment ng OpenAI—kung saan napatunayan itong mas malakas. “Pakiramdam ko talaga ay nakikipagtulungan ako sa isang mas mataas na katalinuhan, at halos may pakiramdam ng paggalang,” sabi ni Pietro Schirano, CEO ng MagicPath, sa isang pahayag na ibinahagi ng OpenAI.
Ang GPT-5.5 Pro, na idinisenyo para sa mas mahirap at mas mataas na katumpakan na trabaho, ay hiwalay na inilalabas sa mga gumagamit ng Pro, Business, at Enterprise sa ChatGPT. Sa BrowseComp, na sumusubok sa kakayahan ng isang modelo na hanapin ang mahirap hanaping impormasyon sa buong web, nakakuha ang GPT-5.5 Pro ng 90.1%, na nangunguna sa Gemini 3.1 Pro sa 85.9%.
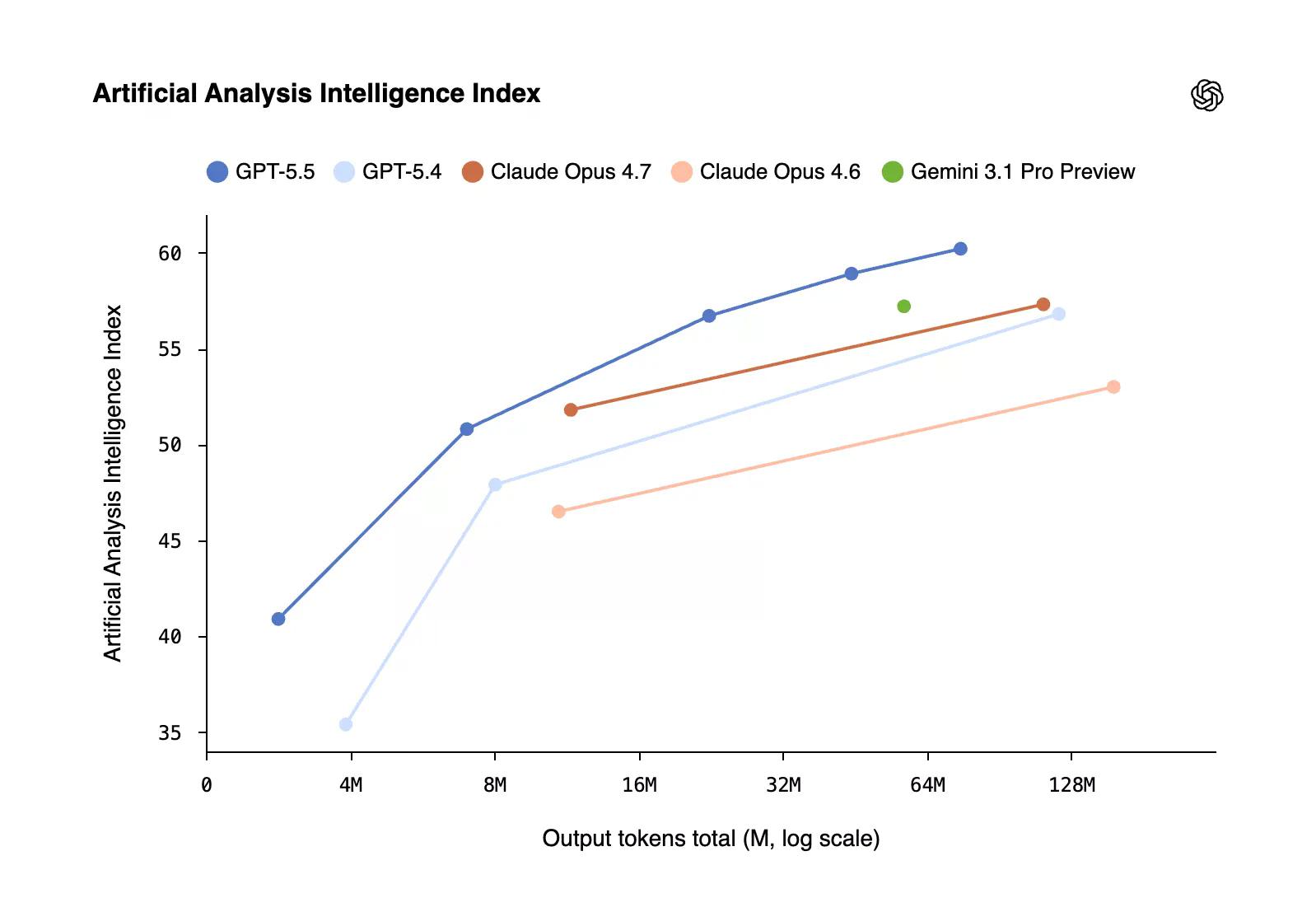
Ang modelo rin ang pinakamatalino sa karaniwan batay sa Artificial Analysis Index. Nag-uulat ang GPT 5.5 ng mas mahusay at kapaki-pakinabang na paggamit ng mga token, na nagbibigay ng mas mahusay na resulta sa pangkalahatan.
Ang pagpepresyo, gayunpaman, ay maaaring makagulat sa ilang gumagamit. Maniningil ang API ng $5 bawat milyong input tokens at $30 bawat milyong output tokens kapag inilunsad ito, na ayon sa OpenAI ay "malapit na." Ang GPT-5.5 Pro sa API ay nagkakahalaga ng $30 bawat milyong input tokens at $180 bawat milyong output tokens.
Ang mga pigurang iyon ay mas mataas kaysa sa GPT-5.4—$2.50 bawat milyong input tokens at $15.00 bawat milyong output tokens—habang ang pagpepresyo para sa GPT-5.5 Pro ay nananatiling pareho sa GPT-5.4 Pro.
Gayunpaman, iginiit ni Sam Altman, CEO ng OpenAI, sa X na ang mga pakinabang sa token efficiency ay pumapawi sa gastos—kinukumpleto ng GPT-5.5 ang parehong mga gawain ng Codex gamit ang mas kaunting token, na nangangahulugang mas murang pagpapatakbo kahit na sa mas mataas na rate per-token.
Bilang paghahambing, ang Xiaomi MiMo v2.5 Pro ay naniningil ng $1 at $3 bawat milyong input at output tokens, ang Minimax M2.7 ay nagkakahalaga ng $0.30 at $1.20 ayon sa pagkakabanggit, at ang Kimi K2.5 ay nangangailangan ng $0.44 at $2.00 bawat milyong token.
