
Ang pangunahing ideya para sa mga AI personal assistant ay laging pareho: Bigyan ng access ang agent sa iyong digital na buhay at ito na ang bahala sa lahat. Ang iyong mga email, iyong kalendaryo, iyong mga tala, iyong mga device—lahat ng iyan. Alam ng iyong AI. Kumikilos ang iyong AI. Ikaw ay natutulog.
Kakatapos lang gumawa ng benchmark ng mga mananaliksik mula sa Huawei Technologies, Beijing Institute of Technology, Peking University, at Chinese Academy of Sciences upang tingnan kung totoo nga ito. Babala: Hindi.
Sinusuri ng Claw-Anything ang mga AI agent sa tatlong dimensyon nang sabay-sabay: mahabang-panahong daloy ng kaganapan na sumasaklaw sa mahigit tatlong buwan ng simulated na aktibidad ng user, magkakaugnay na backend service na may average na 10.1 bawat gawain, at multi-device interaction sa parehong CLI Linux environment at GUI Android environment.
Ang average na context window bawat gawain ay 191,700 salita. Karamihan sa kasalukuyang mga benchmark ay nasa pagitan ng 1,700 at 12,000. Hindi ito maliit na agwat kundi isang ganap na ibang problema. Ito rin ang pakiramdam ng totoong buhay, taliwas sa mga standardized at ultra-specific na benchmark.
Walang ideya ang iyong AI sa nangyayari
Ang benchmark ay may score batay sa pass@1—ang posibilidad na matagumpay na makumpleto ng agent ang isang gawain sa unang pagsubok nito, nang walang muling paggawa. Maaaring hilingin sa agent na mag-cross-reference ng alerto sa presyo ng isang produkto na natagpuan nito ilang linggo na ang nakakaraan, suriin ang kalendaryo ng user para sa isang kaugnay na appointment, at kumilos sa dalawa mula sa isang telepono. Maaaring hilingin din dito na kumuha ng kamakailang trabaho mula sa mga tala, email thread, at Slack, at pagkatapos ay gumawa ng presentasyon mula sa simula.
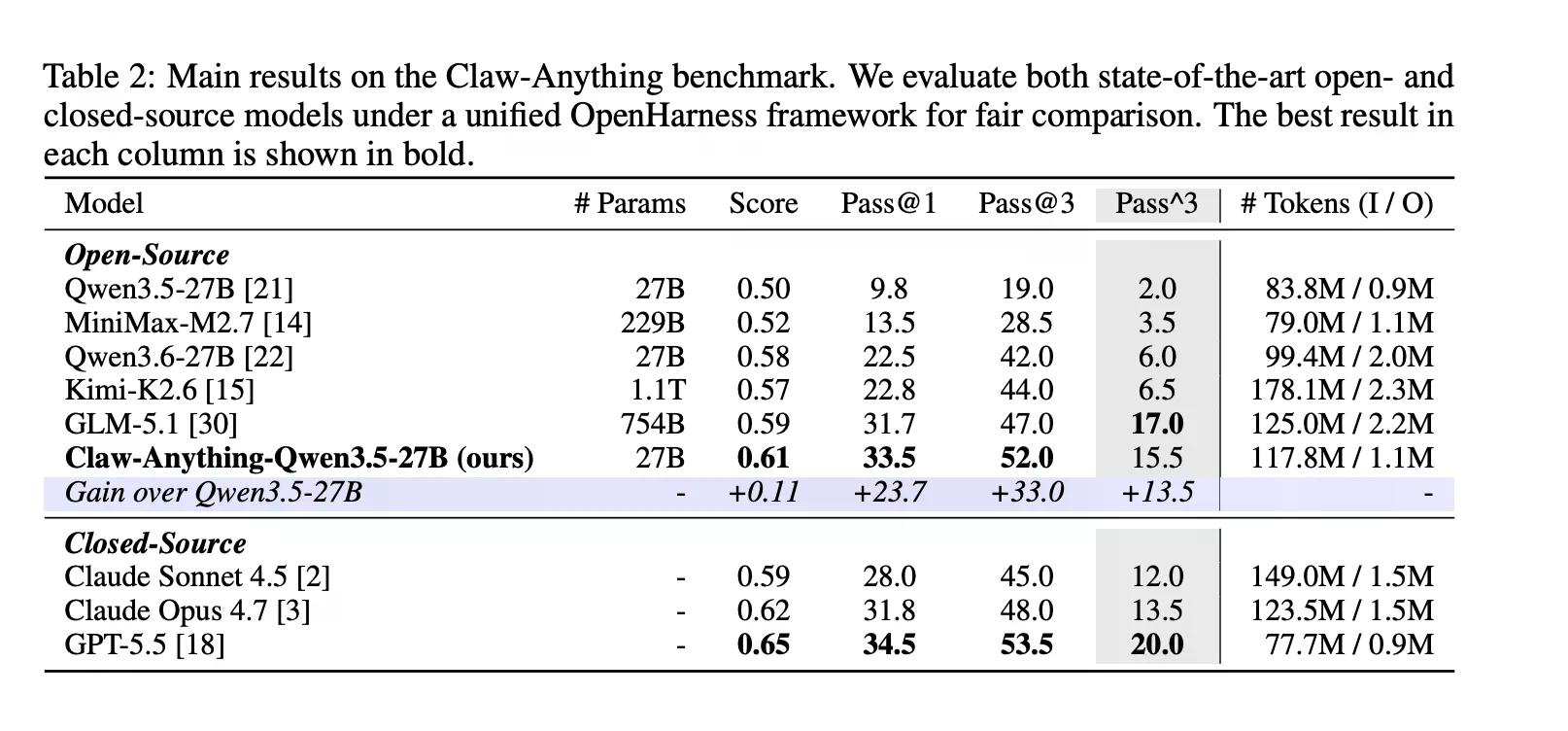
Ito ang mga bagay na talagang ipinapagawa ng mga tao sa mga assistant. Lumalabas na hindi masyadong magaling ang AI sa mga ito. Ang GPT-5.5, ayon sa naunang coverage ng Decrypt, ay ang pinakamahusay na modelo ng OpenAI, na binuo na may layuning agentic at long-horizon na mga gawain. Nakakuha ito ng 34.5%.
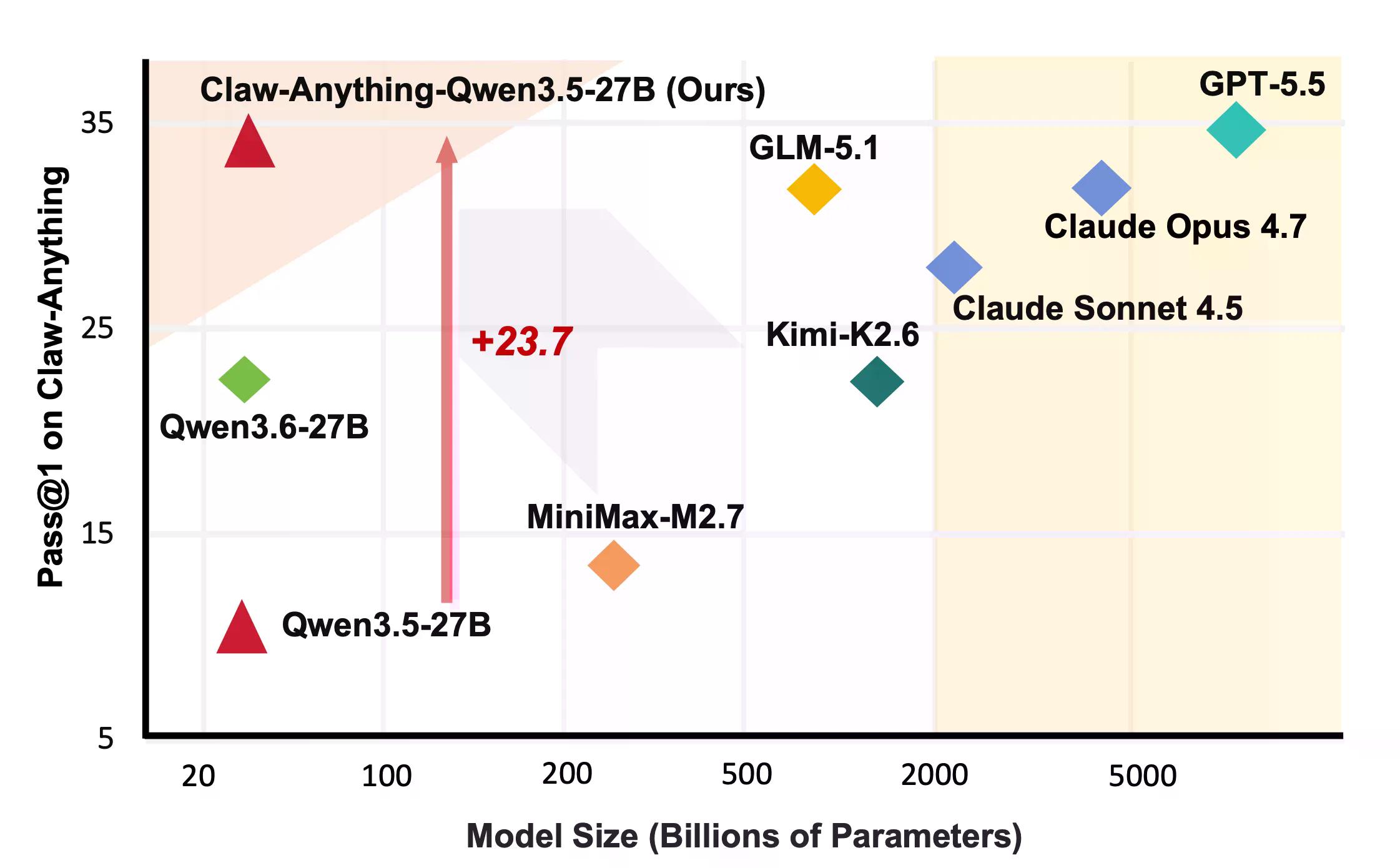
"Ang kasalukuyang mga modelo ay nananatiling hindi maaasahan kahit na bigyan ng mas malawak na access sa digital na mundo ng user," ayon sa papel ng Claw-Anything. Ilang modelo na mukhang kahanga-hanga sa ibang mga benchmark ay bumaba pa ang marka.
Ang benchmark ay nagbibigay din ng grado sa proactive assistance nang hiwalay, ibig sabihin, mga kaso kung saan nakikita ng agent ang isang pangangailangan at kumikilos nang hindi hinihingi. Karamihan sa mga benchmark ay hindi sinusuri ito. Ginagawa ito ng Claw-Anything, at malinaw ang agwat: Nakakuha ang mga agent ng 25.9% sa reactive tasks at 6.7% lang sa proactive ones.
Bakit hindi sinasabi sa iyo ito ng karamihan sa mga benchmark
Naglabas ang mga mananaliksik ng isang matinding argumento: Tinatrato ng kasalukuyang mga benchmark ang mga AI agent na parang task solver na binigyan ng malinis na desk. Tinatrato ng Claw-Anything ang mga ito na parang personal assistant na inihagis sa isang tunay na magulong buhay—mga hindi nauugnay na kaganapan, magkasalungat na signal, buwan-buwan na naipong ingay. Kailangang alamin ng agent kung ano ang mahalaga bago ito makagawa ng anumang kapaki-pakinabang.
Ipinapakita ng mga resulta ng ablation ang pagiging malinaw ng multi-service dependency. Nang tanggalin ang mga tool na kinakailangan para sa cross-service tasks, bumaba sa halos zero ang success rate, dahil karamihan sa mga gawain ay nangangailangan ng mga agent na kumuha ng impormasyon at kumilos sa maraming backend sa halip na sa iisang backend lamang.
Hindi ito bagong uri ng problema sa pagsusuri ng AI. Idineklara ng OpenAI na contaminated ang SWE-bench sa mas maaga ngayong taon matapos bumagsak ang mga score mula humigit-kumulang 70% sa 23% sa isang bersyon na hindi gaanong prone sa leakage. Tungkol iyon sa data hygiene. Ito ay tungkol sa isang bagay na mas pundamental—kung ang mga benchmark ba ay nagtatanong ng tamang tanong.
Sa positibong bahagi, inilabas ng grupo ang pipeline na lumikha ng benchmark kasama ang 2,000 training environment. Ang pag-fine-tune ng Qwen3.5-27B sa 1,500 matagumpay na agent trajectory ay nagpataas ng pass@1 ng 23.7%—sapat upang talunin ang ilang closed-source na modelo sa leaderboard, kabilang ang Claude Sonnet.
Kinilala ng mga mananaliksik ang cross-service coordination bilang pangunahing hamon na nananatili para sa larangan ng benchmark. Ang dataset ay nasa Hugging Face at ang code ay nasa GitHub.
