
Anim na linggo. Ganoon katagal bago nakarating ang Anthropic mula Opus 4.7 patungo sa Opus 4.8.
Ang bagong modelo ay mas mabilis at mas matalino sa mga benchmark test, at may kasamang suite ng mga bagong feature—ngunit hindi gumalaw ang presyo: Ito ay $5 kada milyong input token at $25 kada milyong output token, katulad ng dati.
Mayroon ding fast mode na nagpapatakbo ng parehong modelo sa 2.5 beses na bilis sa halagang $10 input at napakalaking $50 output kada milyon. Sinasabi ng Anthropic na ang rate na iyon ay tatlong beses na mas mura kaysa sa halaga ng fast mode sa mga nakaraang modelo, na magandang paraan para sabihin na mas mahal ito dati.
Ang SWE-bench Pro ay marahil ang pinakamahalagang benchmark na dapat bantayan at upang magkaroon ng ideya kung gaano kagaling ang modelong ito. Sinusukat nito kung ang isang AI ay talagang makakalutas ng mahirap, multi-language software engineering problems na kinuha mula sa mga tunay na codebase ng produksyon—binibigyan ng score bilang porsyento ng mga problemang naipasa.
Sa test na iyon, naabot ng Opus 4.8 ang 69.2%, mas mataas mula sa 64.3% ng Opus 4.7. Ang GPT-5.5 ng OpenAI ay nakakuha ng 58.6%, at ang Gemini 3.1 Pro ng Google ay nahuli sa 54.2%. Para sa isang modelo sa parehong punto ng presyo, iyon ay isang makabuluhang pagtalon.
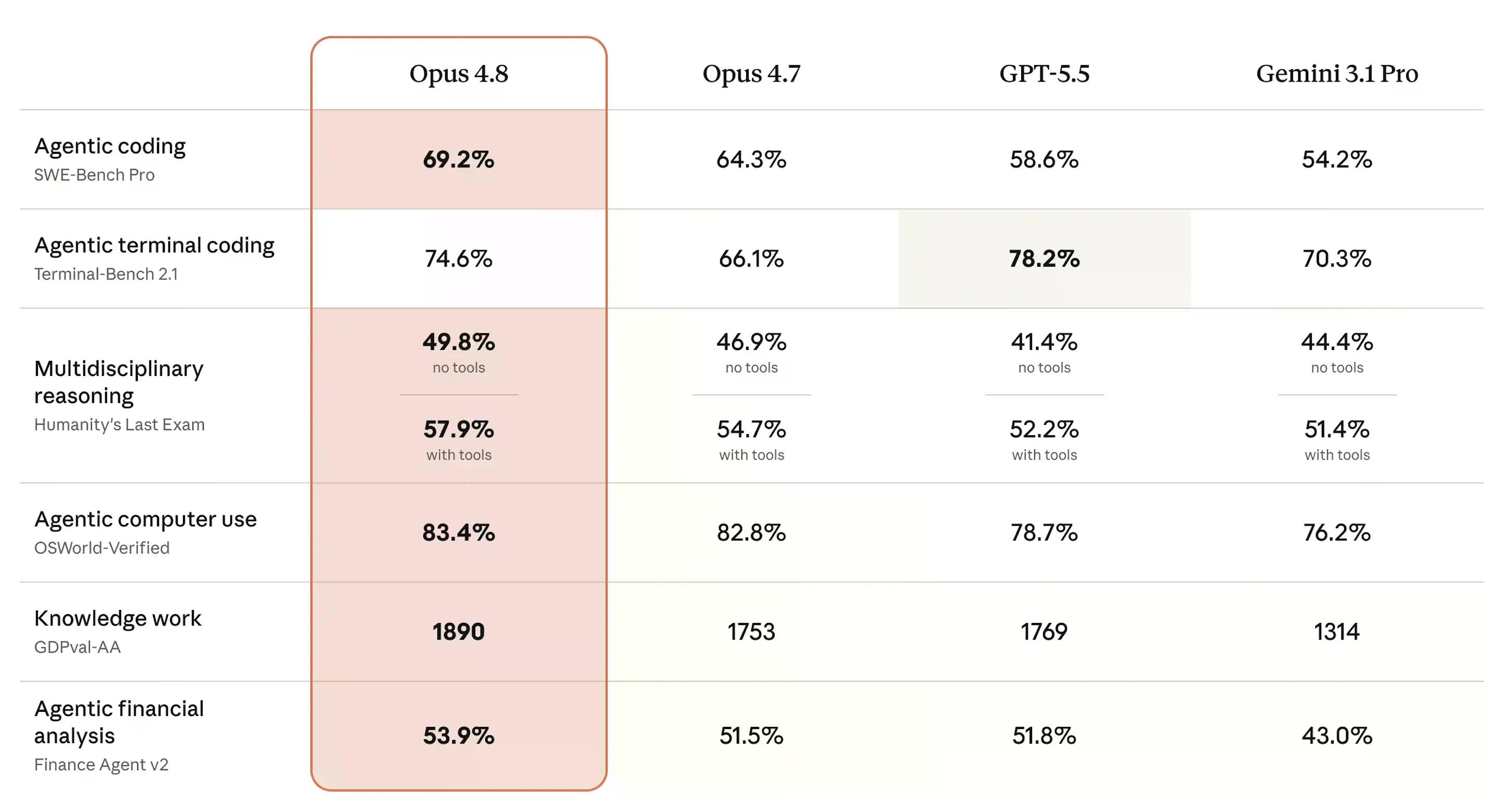
Sa Humanity's Last Exam—mga tanong na pang-eksperto sa iba't ibang akademikong disiplina, binigyan ng score bilang porsyento ng tama—naabot ng Opus 4.8 ang 49.8% nang walang tool at 57.9% na may tool, na mas mataas sa lahat ng tatlong karibal. Ang OSWorld-Verified, na sumusuri sa mga real-world computer use tasks tulad ng pag-navigate sa mga software UI, ay umabot sa 83.4%, bahagyang lumampas sa score ng Opus 4.7 na 82.8%.
Ang tanging pagkatalo: Terminal-Bench 2.1, na sumusukat sa performance ng AI sa mga command-line tasks. Nangunguna ang GPT-5.5 sa 78.2%, habang ang Opus 4.8 ay nakakuha ng 74.6%—mas mahusay kaysa sa 66.1% ng Opus 4.7 at mas mataas sa 70.3% ng Gemini, ngunit ang ikalawang pwesto ay pagkatalo pa rin.
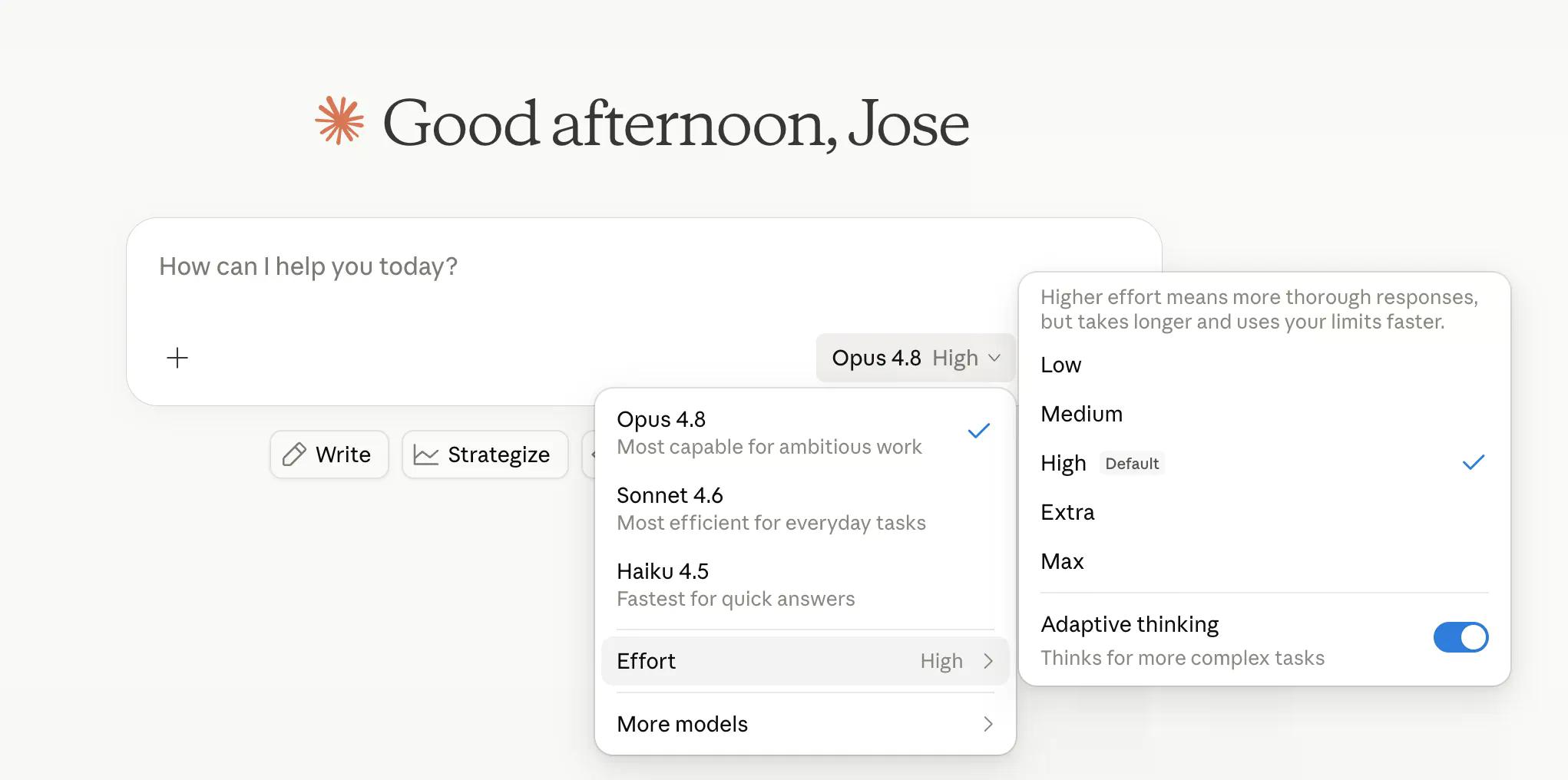
Pinahihintulutan na ngayon ng Anthropic ang mga user na kontrolin kung gaano kahirap mag-isip ang modelo. Ang "High" ang default at mahusay na humahawak sa karamihan ng mga gawain, habang ang "Extra"—tinatawag na "xhigh" sa loob ng Claude Code—ay gumagamit ng mas maraming compute para sa mas mahirap na problema. Ang "Max" ang pinakamataas. Ang "Low" at "Medium" ay naglalaan ng mas kaunting token sa parehong gawain, na nakakatipid ng oras kapalit ng accuracy.
Ang kontrol sa pagsisikap ay katabi ng model selector sa claude.ai at Cowork, na available sa lahat ng plano. Sinasabi ng Anthropic na ang default high ay gumagamit ng halos parehong token tulad ng default ng Opus 4.7 na may mas mahusay na resulta—na kahanga-hangang engineering o magandang messaging, at marahil pareho.
Mahalaga ring tandaan na ang bagong tokenizer ng Anthropic para sa Opus ay gumagamit ng mas maraming token bawat gawain. Kaya, ang mga gumagamit ng Claude ay tiyak na mas magastos upang matapos ang mga bagay, kung pipiliin nila ang Opus sa halip na Claude Sonnet—isang mas mababang kakayahan na modelo, ngunit marahil sapat na para sa pang-araw-araw na gawain at kumplikadong problema na hindi umabot sa antas ng frontier science o coding.
Ang mga limitasyon sa rate sa Claude Code ay tinaasan din upang masakop ang mas mataas na paggamit ng token na ginagawa ng mga setting na Extra at Max.
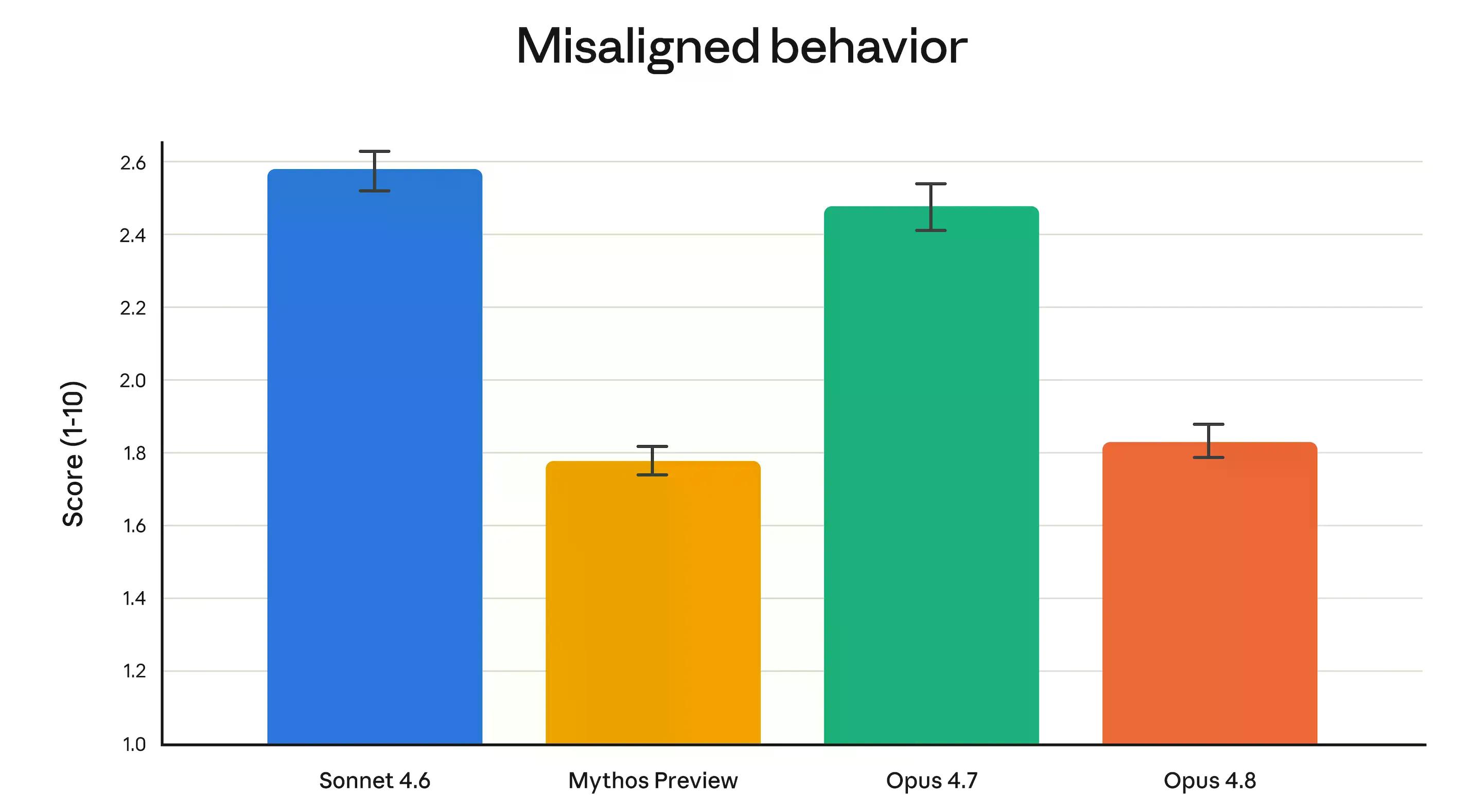
Sinabi ng alignment team ng Anthropic na ang Opus 4.8 "ay umabot sa bagong mataas na antas sa aming mga sukatan ng prosocial traits tulad ng pagsuporta sa awtonomiya ng user at paggawa ng pinakamahusay para sa interes ng user." Mas konkretong: ang mga rate ng panlilinlang at maling paggamit-kooperasyon ay mas mababa kaysa sa Opus 4.7, at maihahambing sa Claude Mythos Preview—ang pinakarestriktibong modelo ng Anthropic.
Apat na beses ding mas mababa ang posibilidad ng Opus 4.8 na palampasin ang mga bug sa sarili nitong code nang hindi ito sinasabi, kumpara sa 4.7.
Ang paghahambing sa Mythos ay nangangailangan ng konteksto. Ang Mythos ay isang tier sa itaas ng Opus—inilalarawan ito ng Anthropic bilang "mas malaki at mas matalino kaysa sa aming mga modelo ng Opus." Sa kasalukuyan, ito ay umiiral lamang bilang isang preview, na naa-access sa iilang piling organisasyon na nagsasagawa ng cybersecurity work sa pamamagitan ng Project Glasswing.
Natuklasan ng AI Security Institute ng U.K. na kaya nitong tapusin nang awtonomiya ang "The Last Ones," isang 32-hakbang na simulation ng pag-atake sa corporate network na karaniwang inaabot ng 20 oras para sa mga human red team. Iyan ang dahilan kung bakit hindi pa ito ibinebenta. Sinasabi ng Anthropic na may mas matibay na cyber safeguards na ginagawa, at inaasahang ilalabas ang mga modelong Mythos-class sa lahat "sa mga darating na linggo."
Available din ngayon: dynamic workflows sa Claude Code, sa research preview. Pinahihintulutan ng feature na ito si Claude na sumulat ng sarili nitong orchestration scripts at magpatakbo ng parallel subagents sa isang session, i-verify ang kanilang mga output, at mag-ulat—tulad ng ginagawa ni Hermes noon.
Ang mga dynamic workflow ay available para sa mga user ng Enterprise, Team, at Max plan, at sinasabi ng Anthropic na gumagamit ang mga ito ng mas maraming token kaysa sa karaniwang Claude Code session.
Ang pagpepresyo ng Anthropic na $5/$25 ay lubhang naiiba kumpara sa ginagawa ng China kamakailan.
Ginawa ng DeepSeek V4 Pro na permanente ang 75% discount nito noong nakaraang linggo: $0.435 bawat milyong input token at $0.87 bawat milyong output token. Ang Xiaomi MiMo V2.5 Pro ay tumatakbo sa parehong rates sa pamamagitan ng mga provider tulad ng OpenRouter.
Ang fast mode ng Anthropic ay nagkakahalaga ng $10 input at $50 output kada milyon—mas mahal kaysa sa karaniwang Opus 4.8 mismo, at humigit-kumulang 57 beses na mas mahal bawat output token kaysa sa DeepSeek V4 Pro. Nagastos na ng milyon-milyong dolyar ang mga korporasyon sa inference sa mga American model. Kung gagamitin ang Opus nang labis, mabilis na aabot sa milyon-milyong dolyar ang iyong negosyo.
Ang sagot ng Anthropic sa agwat ng presyo ay kalidad at kaligtasan. Sa SWE-bench Pro, mas mahusay ang Opus 4.8 kaysa sa parehong Chinese models. Sa alignment, walang sinuman ang nakalapit sa mga benchmark na inilathala ng Anthropic.
Ang mga bagay na iyon ay mahalaga sa mga production environment kung saan ang isang modelo na tahimik na nakikipagtulungan sa masamang input ay isang aktwal na panganib—sa mga regulated industry, legal work, at anumang sitwasyon kung saan ang "mukhang maayos naman" ay hindi katanggap-tanggap na post-incident report. Para sa iba, mahirap balewalain ang agwat.
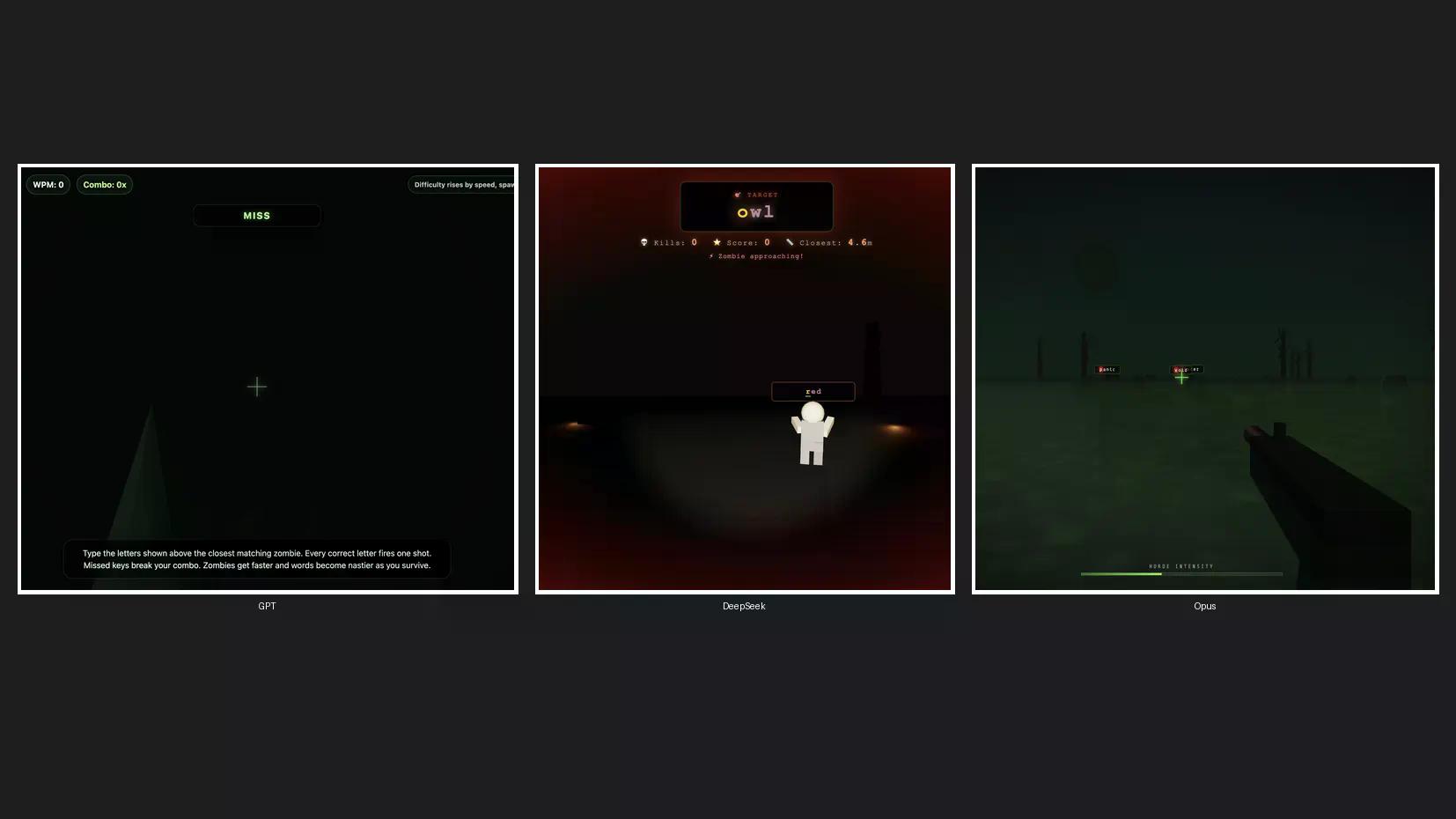
Nagsagawa kami ng mabilis na coding test upang lumikha ng isang 3D zombie game para makita kung paano inihambing ang Claude Opus 4.8 sa ChatGPT at DeepSeek, arguably ang pinakapopular na kakumpitensya nito mula sa U.S. at China. Itinakda namin ang Opus 4.8 sa default high, GPT-5.5 sa high effort, at DeepSeek V4 Pro sa high effort—tatlong modelo, isang prompt, walang pag-uulit.
Nauna ang GPT-5.5. Ang laro nito ay walang zombie visuals at walang sound effects. Ito ay mabilis, oo, ngunit hindi nito natugunan nang lubusan ang brief.
Pangalawa ang DeepSeek V4 Pro na may mouse movement, aktwal na mga karakter ng zombie, sound effects, solidong mekanismo, at malinis na aesthetic. Walang reklamo doon.
Ang Opus 4.8 ay tumagal ng halos tatlong beses kaysa sa GPT-5.5, ngunit nagbigay ng pinakamahusay na splash screen, pinakamahusay na disenyo ng zombie, pinakamahusay na mekanismo ng laro, at disenteng sound effects. Ito ang pinakamabagal, ngunit ang pinakamahusay na output. Gayunpaman, marahil hindi ito sapat upang bigyang-katwiran ang paggamit nito kaysa sa DeepSeek, dahil sa agwat ng gastos.
Lahat ng laro ay available sa aming Itch.io Profile. Ang GPT-5.5 ay gumawa ng Zombie Typing, ang Opus ay gumawa ng Typing Dead, at ang DeepSeek v4 Pro ay gumawa ng laro na walang pangalan na direktang magdadala sa iyo sa aksyon. Tawagin natin itong TypeSeek.
Isang buong comparative review ang darating. Sa ngayon: Mas mahusay mag-code ang Claude Opus 4.8 kaysa sa GPT-5.5 at Opus 4.7 para sa ganitong uri ng gawain, sa parehong presyo na sinisingil ng Anthropic mula pa noong 4.7. Ang mga developer na nagbabayad na ng $5 kada milyong token ay nakakuha lang ng mas mahusay na modelo nang libre.
