
Tanungin ang lima sa pinaka-advanced na AI systems sa mundo kung ang isang pahayag ay totoo, at sa dalawang-katlo ng mga pagkakataon, hindi bababa sa isa ang magbibigay sa iyo ng ibang sagot. Ito ang natuklasan ng isang bagong pag-aaral na inilathala ngayong buwan ng mananaliksik na si Kosta Jordanov sa Lenz Research.
Binigyan ng pag-aaral ang GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 Pro with Search, at Sonar Pro ng parehong 1,000 tunay na claims para sa fact-check na isinumite ng mga aktuwal na gumagamit. Kinailangan ng mga modelo na pumili ng isa sa apat na label: totoo, halos totoo, nakapanliligaw, o mali.
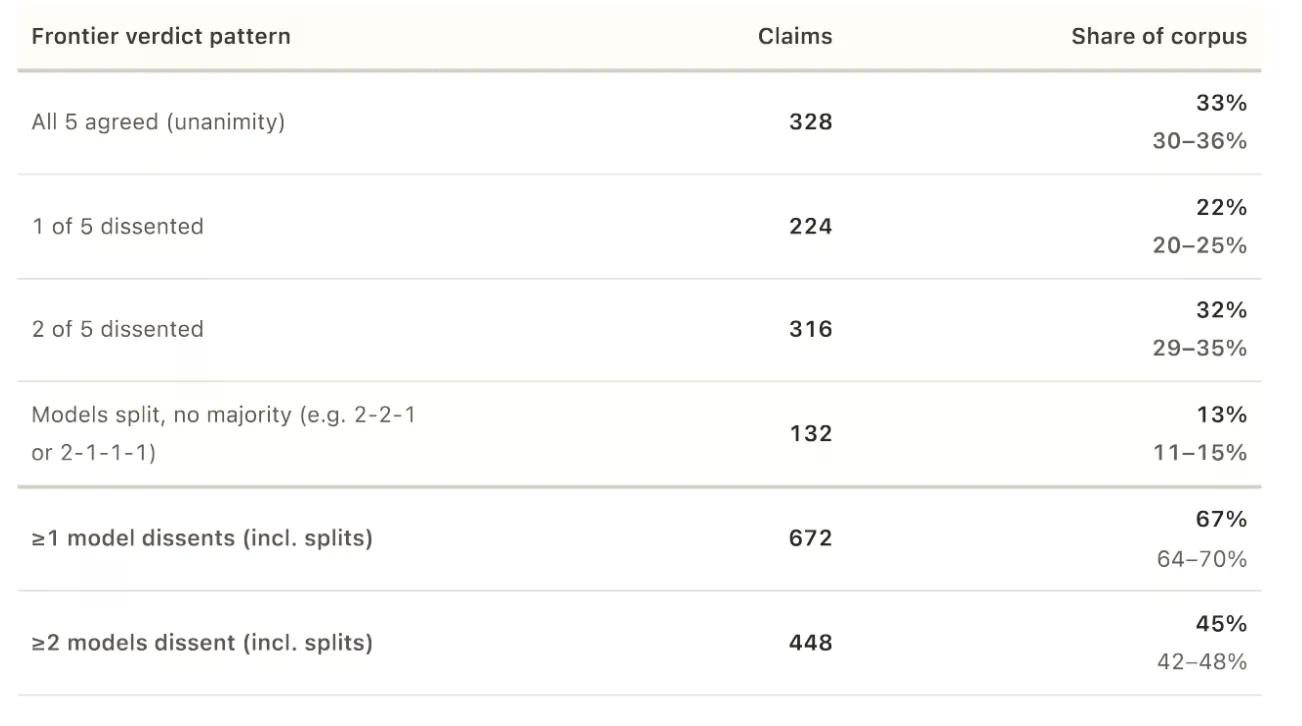
Sa 672 sa 1,000 claims, hindi bababa sa isang modelo ang lumihis sa mayorya. Sa 34% ng mga kaso, matindi ang hindi pagkakasundo: tinawag ng isang modelo ang isang claim na totoo habang tinawag naman ito ng isa pang modelo na mali.
“Hindi ito mga benchmark item na may pampublikong answer keys—ito ay mga claims na isinumite ng mga tunay na gumagamit para sa pagpapatunay sa isang fact-checking platform,” sabi ng pag-aaral. “Isa lamang sa mga kategorya ng hatol ang maaaring tama sa bawat claim, kaya ang anumang hindi pagkakasundo sa pagitan ng panel ay nangangahulugan na ang hatol ng hindi bababa sa isang modelo ay hindi tumutugma sa label sa ilalim ng 4-na-kategoriya na rubrik na ito.”
Ipinakita ng mga naunang pag-aaral sa AI hallucination na ang mga chatbot ay nag-iimbento ng mga katotohanan. Iyan ay isang problema. Ito ay iba. Hindi kinakailangang gumawa ng mga bagay ang mga modelo, hindi lang sila nagkakasundo sa mga pangunahing paghusga sa katotohanan tungkol sa parehong materyal.
Gumamit ang pananaliksik ng isang setup na nagpapahirap sa mga kumpanya ng AI na ipaliwanag ang mga ito. Sa halip na kumuha ng mga claims mula sa mga standard test set—ang uri na madalas na lumalabas sa training data—ginamit ng mga mananaliksik ang mga claims na isinumite ng mga tunay na tao sa fact-checking platform ng Lenz. “Karamihan sa mga claims na ito ay malamang na hindi lumabas sa anumang training corpus na may gold label—walang canonical answer key na maaaring gamitin sa pattern-matching, walang benchmark leaderboard na pagbabasehan,” tala ng papel.
Ang statistical na sukat ng pagkakasundo, na tinatawag na Krippendorff’s alpha, ay umabot sa 0.639 sa isang iskala kung saan ang 1.0 ay nangangahulugang perpektong pagkakasundo at ang 0 ay nangangahulugang random na pagkakataon. Sinasabi ng pag-aaral na ito ay nagpapahiwatig ng “hindi maliit ngunit limitadong pagkakasundo.” “Ang mga hatol ng mga modelo ay may istraktura sa halip na random, ngunit hindi sapat ang pagiging konsistent upang ituring ang panel bilang isang nag-iisang mapagpalit na hukom,” tala ng mga mananaliksik. Karaniwang itinuturing ng mga mananaliksik na mahina ang anumang nasa ibaba ng 0.8.
Nang magkasundo ang lahat ng limang modelo—na nangyari lamang sa 328 sa 1,000 claims—halos hindi sila kailanman nagkasundo na ang isang bagay ay nakapanliligaw o halos totoo. Apat na claims lamang ang nakakuha ng nagkakaisang hatol na “nakapanliligaw.” Wala namang nakakuha ng nagkakaisang “halos totoo.”
Nagbigay ang mga mananaliksik ng mga halimbawang claims kung saan ipinakita ng mga modelo ng AI ang pinakamalaking pagkakaiba, kabilang ang "Ang aktibong portfolio ng World Bank sa Nigeria ay lumalagpas sa $16.4 bilyon hanggang 2025." Sinabi ng ChatGPT 5.4 na ito ay "halos totoo" habang tinawag ito ng Gemini 3 Pro na "mali" at ang kapatid nitong modelo na Gemini 3 Pro + Search ay tinasa itong "nakapanliligaw."
Sa isa pang halimbawa, binigyan ang mga modelo ng claim: "Sinabi ni Donald Trump na ipinagpaliban ang isang pag-atake sa Iran sa kahilingan ng Gulf Allies." Sinabi ng GPT-5.4 na ito ay mali, tinawag ito ng Claude Opus 4.7 na halos totoo, sinabi ng Gemini 3 Pro na mali, at tinasa ito ng Gemini 3 Pro + Search na totoo.
“Ang panel ay nagtatagpo sa mga depinitibong hatol; ang gitna ng rubrik ang bahaging nagkakawatak-watak,” natuklasan ng mga mananaliksik. Nangyari lamang ang pagkakaisa sa mga sukdulan: kung ang claim ay tiyak na totoo o tiyak na mali.
Mahalaga ito dahil parami nang parami ang mga tao na bumaling sa mga AI system para sa fact-checking. Kung ipinidikit mo ang isang claim mula sa isang balita sa ChatGPT, Claude, o Gemini, maaari kang makakuha ng tatlong magkakaibang sagot. Alin ang iyong pagkakatiwalaan?
Gustung-gusto ng mga kumpanya ng AI na sabihin sa iyo na nagiging mas tumpak ang kanilang mga modelo. Naglalathala sila ng mga benchmark score na nagpapakita ng patuloy na pagpapabuti. Ngunit sinubukan ng pag-aaral ng Lenz ang mga modelong ito sa uri ng magaspang, malabong claims na pinag-aawayan ng mga tunay na tao—at natuklasan na ang mga modelo ay nag-aaway din.
Maingat ang papel na ituro ito. “Ang mayorya ng mga nangungunang modelo ay hindi ground truth. Ang hatol ng mayorya ay minsan mali; ang isang indibidwal na tumututol na modelo ay minsan tama. Ginagamit namin ang mayorya bilang structural reference point para sa pagsukat ng hindi pagkakasundo, hindi bilang kapalit ng kawastuhan.”
May mas malalim na problema na nakatago sa mga numero. Kapag hindi nagkasundo ang mga modelo, hindi bababa sa isa sa kanila ang mali—tinatawag ng pag-aaral ang hatol ng isang modelo na “hindi tumutugma sa label sa ilalim ng 4-na-kategoriya na rubrik na ito.” Walang mekanismo para sa tie-breaker, walang korte ng apela. Ang kamakailang pag-uulat tungkol sa pagiging maaasahan ng AI ay nagtaas ng mga katulad na alarma.
Sa 328 claims kung saan nagkasundo ang lahat ng limang modelo, walang nakakuha ng nagkakaisang “halos totoo.” Ganap na nawalan ng laman ang nuance bucket. Kung ang mga modelo ng AI ay makakahanap lamang ng pagkakaisa sa mga sukdulan, maaasahan ba sila bilang mga fact checker?
