
بسیاری از مردم شیائومی را به عنوان برند چینی گوشی میشناسند. همان شرکتی که اسکوترهای برقی ارزان و تصفیه کنندههای هوا میسازد. دقیقاً شرکتی نیست که انتظار داشته باشید یک دوشنبه صبح رکورد اصلی سرعت پردازش استنتاجی هوش مصنوعی را بشکند.
و با این حال. شیائومی به تازگی MiMo-V2.5-Pro-UltraSpeed را منتشر کرده است، حالتی برای ارائه مدل پرچمدار تریلیون پارامتری خود که به بیش از 1000 توکن در ثانیه میرسد – و در دموها به نزدیکی 1200 توکن نیز میرسد.
پارامترها وزنهای عددی داخلی هستند که نحوه تفکر یک مدل را تعریف میکنند – هرچه بیشتر داشته باشید، الگوهای پیچیدهتری را میتواند تشخیص دهد. توکنها قطعاتی از متن هستند که مدل میخواند و مینویسد، به طور متوسط تقریباً سه چهارم یک کلمه.
شیائومی این کار را بر روی یک نود تجاری 8-GPU انجام داد. سختافزار استاندارد، بدون تراشههای سفارشی. این امر محاسبات را برای اینکه چه کسی واقعاً میتواند این نوع سرعت را در تولید (production) مستقر کند، تغییر میدهد.
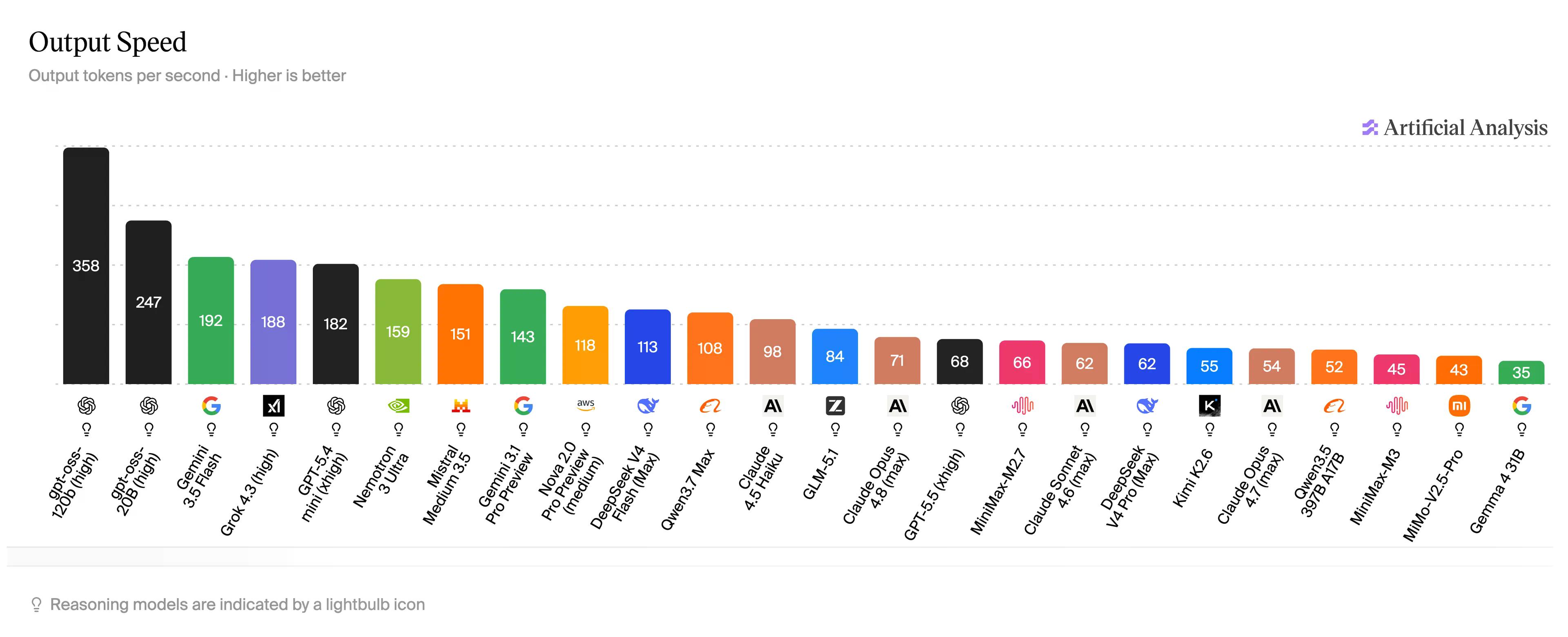
برای بیان این عدد به زبان ساده: طبق تحلیل Artificial Analysis، GPT-5.5 – که بیشتر کاربران ChatGPT در واقع با آن صحبت میکنند – در 68 توکن قرار دارد. Claude Opus 4.6 با مدل پایینتر، Haiku، در حدود 71 توکن و به 98 توکن در ثانیه میرسد. Gemini Flash به 192 توکن در ثانیه میرسد. MiMo-V2.5-Pro-UltraSpeed به 1000 توکن در ثانیه میرسد، آن هم با مدلی که در معیارهای کدنویسی با Opus برابری میکند.
شرکتهای Cerebras و Groq کسبوکارهای کاملی را حول این مشکل بنا کردهاند. Cerebras یک تراشه به اندازه یک بشقاب شام طراحی کرده است که 44 گیگابایت حافظه روی تراشه دارد تا گلوگاه پهنای باند را که سرعت استنتاج GPU را کاهش میدهد، از بین ببرد. این تراشه به 969 توکن در ثانیه در مدل Llama 3.1 405B متا دست یافت – چشمگیر است، اما این یک مدل 405 میلیارد پارامتری است که کمتر از نیمی از اندازه MiMo-V2.5-Pro است. معماری سفارشی واحد پردازش زبان (LPU) شرکت Groq بسته به مدل، به حداکثر 300 تا 750 توکن در ثانیه میرسد.
هیچکدام از اینها بر روی سختافزاری اجرا نمیشوند که بتوانید امشب از AWS اجاره کنید.
شیائومی این کار را بر روی GPUهای تجاری تنها از طریق نرمافزار انجام داد – ترکیبی از ترفندهای در سطح مدل و یک موتور پردازش استنتاجی اختصاصی به نام TileRT.
دو تکنیک این سرعت را فراهم میکنند. تکنیک اول کوانتیزاسیون FP4 نام دارد: به جای اجرای مدل با دقت عددی کامل 8 بیتی یا 16 بیتی، شیائومی لایههای تخصصی را – که بیشتر یک تریلیون پارامتر را تشکیل میدهند – به 4 بیت کاهش میدهد. حجم حافظه کاهش مییابد، فشار پهنای باند کاهش مییابد، و سرعت افزایش مییابد. معمولاً اشکال این کار کاهش جزئی کیفیت است. راهحل شیائومی دقیق است: فقط لایههای تخصصی فشرده میشوند، بقیه با دقت کامل باقی میمانند. با این رویکرد، کاهش کیفیت تقریباً صفر توصیف شده است.
دومین تکنیک رمزگشایی گمانهزنانه DFlash است. در رمزگشایی گمانهزنانه معمولی، یک مدل پیشنویس کوچک چند توکن بعدی را حدس میزند، سپس مدل بزرگ آنها را به صورت موازی تأیید میکند. DFlash به طور کامل از پیشنویس متوالی صرفنظر میکند – یک بلوک کامل از موقعیتهای ماسک شده را در یک گذر (forward pass) پر میکند. در کارهای کدنویسی، مدل بزرگ به طور متوسط 6.3 از 8 توکن پیشنهادی را در هر دور تأیید میپذیرد. این یعنی شش توکن در یک مرحله تأیید میشوند به جای یک توکن.
TileRT اینها را به هم پیوند میزند. این سیستم کل خط لوله محاسباتی را به طور پیوسته در GPU نگه میدارد – بدون سربار راهاندازی هر اپراتور، بدون شکافهای اجرایی.
شیائومی این رویکرد را "طراحی مشترک مدل-سیستم افراطی" مینامد و این عبارت دقیق است: هیچ یک از این تکنیکها به تنهایی به 1000 توکن در ثانیه نمیرسد، اما همافزایی بین همه رویکردها این کار را انجام میدهد.
MiMo-V2.5-Pro یک مدل در سطح پیشرو است. ما عرضه V2.5 Pro را در آوریل پوشش دادیم – این مدل در بیشتر معیارهای کدنویسی با Claude Opus برابری میکند و با هزینه تقریبی 0.43 دلار ورودی / 0.87 دلار خروجی به ازای هر میلیون توکن اجرا میشود. Opus به ازای هر میلیون توکن 5 دلار ورودی / 25 دلار خروجی هزینه دارد.
UltraSpeed دقیقاً همان مدل MiMo V2.5 Pro را تسریع میکند، نه یک نسخه سادهشده را.
سرعت استنتاج کافی، نحوه استفاده از مدل را تغییر میدهد. شما میتوانید دهها مسیر استدلالی را به صورت موازی اجرا کنید به جای اینکه منتظر یک پاسخ باشید. تشخیص کلاهبرداری، تولید سیگنال معاملاتی، حلقههای عامل بیدرنگ – همه اینها محدودیتهای تأخیر سختی دارند که 60 توکن در ثانیه نمیتوانند آنها را برآورده کنند. با سرعت 1000 توکن در ثانیه، این امکان فراهم میشود.
شیائومی این سرعت را با نرخی 3 برابر نرخ استاندارد MiMo-V2.5-Pro برای تقریباً 10 برابر خروجی قیمتگذاری کرده است. دوره آزمایشی API از 9 تا 23 ژوئن اجرا میشود، بر اساس درخواست، با اولویت برای توسعهدهندگان سازمانی و حرفهای. checkpoint FP4-DFlash از قبل در Hugging Face برای آزمایش جامعه متن باز (open-sourced) شده است.
