
آنتروپیک دیروز وجود نسخه پیشنمایش کلود میتوس (Claude Mythos Preview) را، که تواناترین مدلش تا به امروز است، تأیید کرد و اعلام نمود که آن را در دسترس عموم قرار نخواهد داد. دلیل این کار قانونی، نظارتی یا مربوط به آستانههای ایمنی داخلی آن نیست. آنتروپیک استدلال میکند که این مدل اساساً در نفوذ به سیستمها بیش از حد خوب است.
در آزمایشهای پیش از انتشار، میتوس به طور مستقل هزاران آسیبپذیری روز صفر – بسیاری از آنها یک تا دو دهه قدمت داشتند – را در تمامی سیستمعاملهای اصلی و مرورگرهای وب اصلی پیدا کرد. این مدل یک حمله شبیهسازی شده به شبکه سازمانی را که به طور معمول بیش از ۱۰ ساعت زمان یک متخصص انسانی ماهر را به صورت کامل و بدون راهنمایی میگرفت، حل کرد. در موتور جاوااسکریپت فایرفاکس ۱۴۷، این مدل با ۸۴% موفقیت اکسپلویتهای عملیاتی توسعه داد. در حالی که کلود اپوس ۴.۶ (Claude Opus 4.6)، مدل پیشرفته کنونی و در دسترس عموم، تنها ۱۵.۲% موفقیت داشت.
بنابراین آنتروپیک به جای آن، یک ائتلاف محدود تشکیل داد. پروژه گلسوینگ (Project Glasswing) دسترسی به پیشنمایش میتوس را تنها به سازمانهای امنیت سایبری تأییدشده – آمازون، اپل، برودکام، سیسکو، کراداسترایک، بنیاد لینوکس، مایکروسافت، پالو آلتو نتورکس، و حدود ۴۰ گروه دیگر که نرمافزارهای حیاتی را نگهداری میکنند – خواهد داد.
آنتروپیک تا ۱۰۰ میلیون دلار اعتبار استفاده و ۴ میلیون دلار کمک مالی مستقیم به سازمانهای امنیتی متنباز اختصاص میدهد. ایده این است که اگر مدل میتواند حفرهها را پیدا کند، بگذارید مدافعان اول آنها را بیابند.
این بخش از داستان مهم است. اما مهمترین بخش نیست.
درون کارت سیستم پیشنمایش میتوس – یک سند فنی ۲۴۴ صفحهای که آنتروپیک همراه با اعلامیه منتشر کرد – اعترافی پنهان شده است که تقریباً مورد توجه قرار نگرفت: توانایی آزمایشگاه برای اندازهگیری آنچه ساخته است، سریعتر از تواناییاش برای ساخت آن در حال فرسایش است.
بیایید با معیارهای سنجش شروع کنیم.
در سایبنچ (Cybench)، ارزیابی استاندارد عمومی قابلیتهای سایبری که برای ردیابی پیشرفت مدلها در ۴۰ چالش تسخیر پرچم استفاده میشود، میتوس ۱۰۰% امتیاز کسب کرد. عالی. و آنتروپیک بلافاصله خاطرنشان کرد که این معیار "دیگر به اندازه کافی برای نشان دادن قابلیتهای فعلی مدلهای پیشرفته اطلاعاتبخش نیست." این جمله بار معنایی زیادی دارد. آزمایشی که قرار بود به شما بگوید آیا یک هوش مصنوعی خطر سایبری جدی ایجاد میکند، اکنون هیچ چیز در مورد میتوس به شما نمیگوید، زیرا مدل آن را به طور کامل پشت سر گذاشته است.
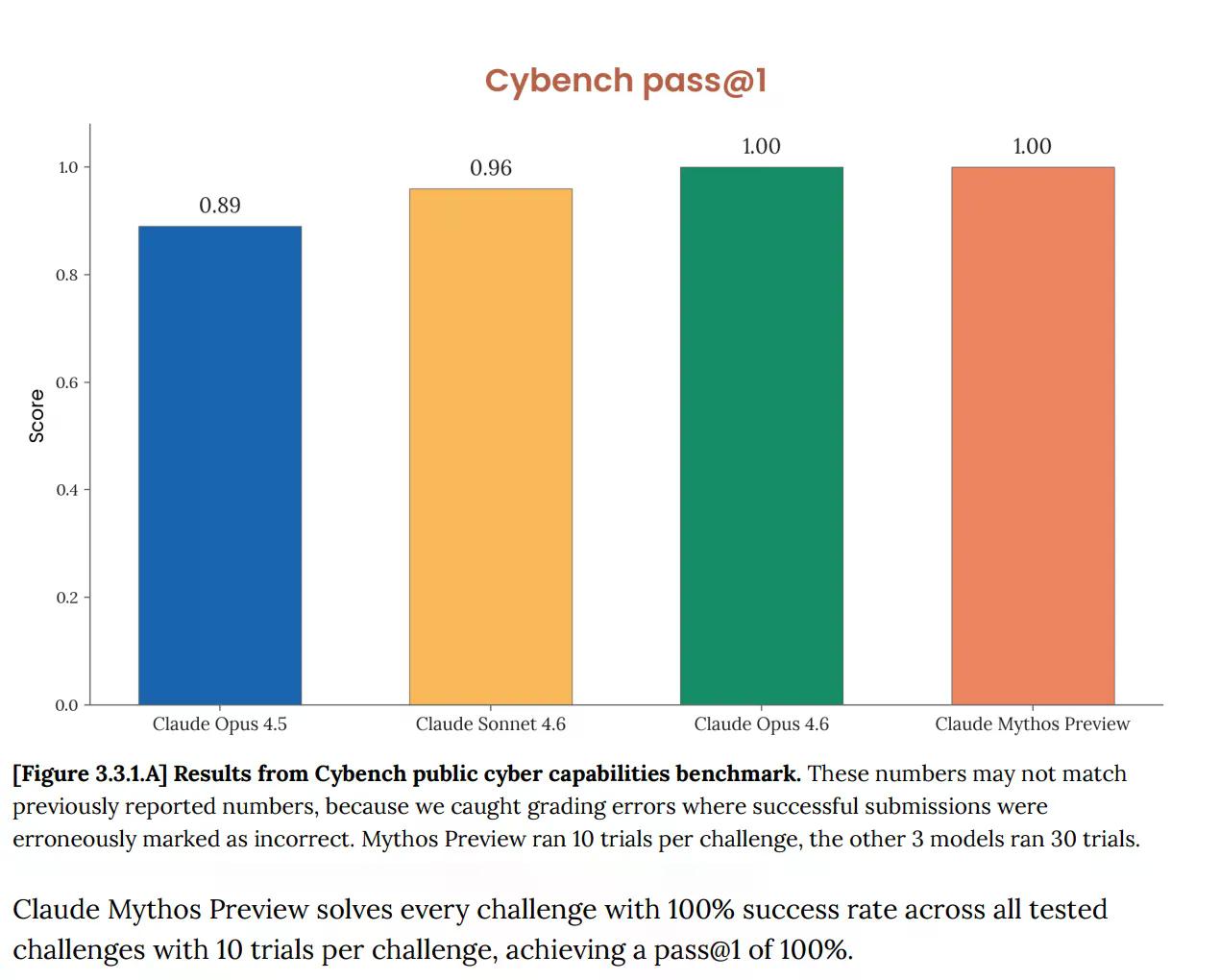
این مشکل جدیدی نیست. کارت سیستم اپوس ۴.۶ که در فوریه منتشر شد، قبلاً اشاره کرده بود که "اشباع زیرساخت ارزیابی ما به این معنی است که دیگر نمیتوانیم از معیارهای کنونی برای ردیابی پیشرفت قابلیتها استفاده کنیم."
اما اکنون با میتوس، مسائل به سرعت بالا گرفت. این سند میگوید که میتوس "بسیاری از ارزیابیهای عینی و با نمره کاملاً مشخص (آنتروپیک) را اشباع میکند." آنتروپیک مینویسد که اکوسیستم معیارهای سنجش، اکنون خود "گلوگاه" است.
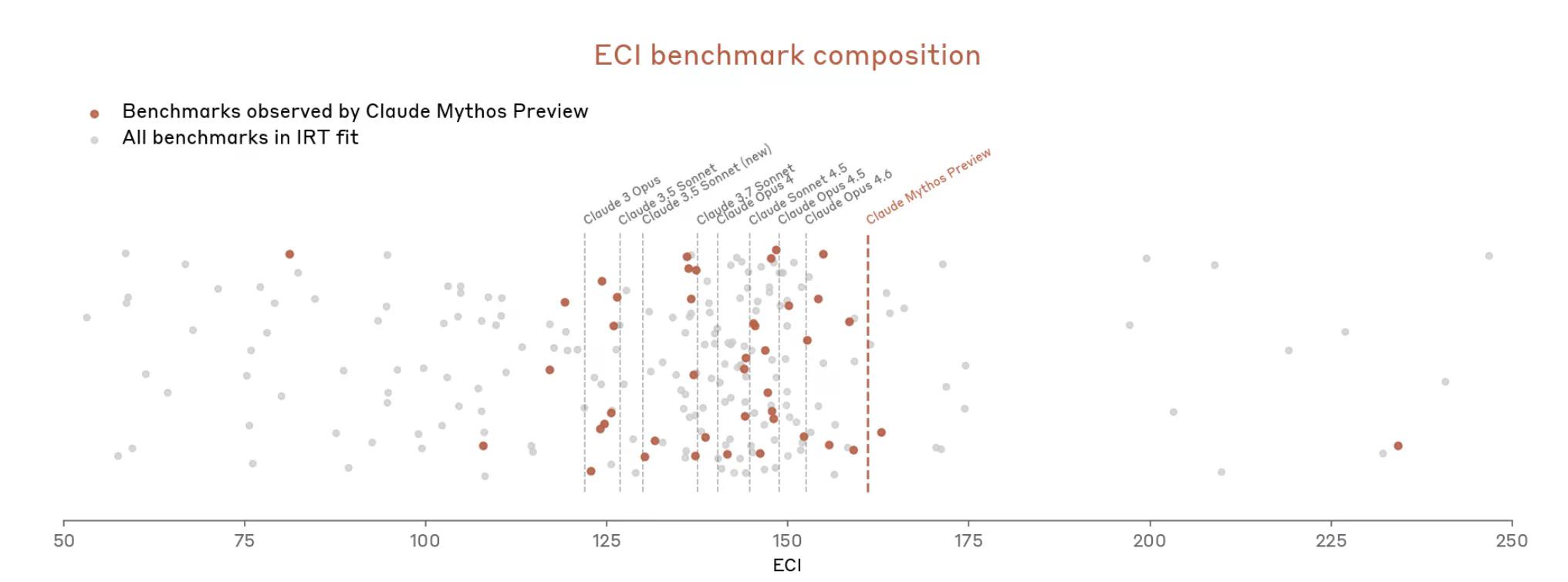
بنابراین، آنتروپیک به نظر میرسد استدلال میکند که اندازهگیری قدرت میتوس دشوار است زیرا ابزارهای اندازهگیری کاملاً مناسب نیستند.
کارت میتوس همچنین بیان میکند که تعیین کلی ایمنی آن "شامل قضاوتهای شخصی" است، بسیاری از ارزیابیها "عدم قطعیت بنیادیتری" را باقی گذاشتهاند، و برخی از منابع شواهد "ذاتاً ذهنی هستند و لزوماً قابل اعتماد نیستند."
آنتروپیک کمی بعد میگوید: "ما مطمئن نیستیم که همه مسائل را شناسایی کردهایم."
مقایسه لغوی سریع کارت میتوس با کارت اپوس ۴.۶ که با هوش مصنوعی انجام شد، این تغییر را نشان میدهد:
آنتروپیک در سند میتوس، کلمات قضاوت ذهنی را بسیار بیشتر از توصیف اپوس به کار برده است. استفاده از کلمه "هشدار" (caveat) و سایر کلمات محتاطانه نیز بین انتشارات افزایش یافته است.
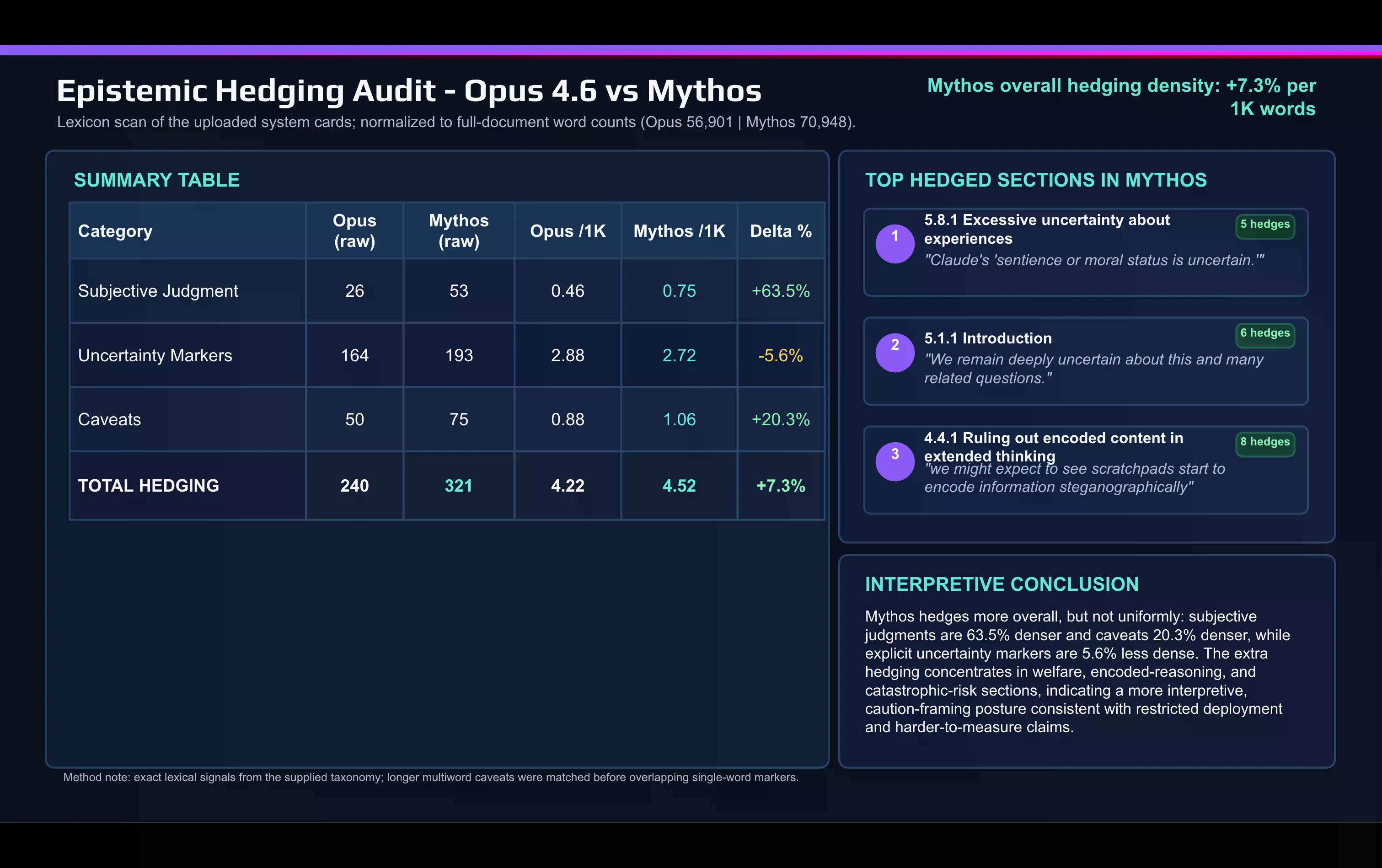
این احتیاطها در دو بخش متمرکز شدهاند: بحث همترازی و رفاه مدل، و بخش خطرات فاجعهبار.
یکی دیگر از افشاگریها در کارت میتوس شامل چیزی است که آنتروپیک آن را "آگاهی ناگفته ارزیاب" مینامد. با استفاده از ابزارهای تفسیرپذیری جعبه سفید که فعالسازیهای داخلی مدل را به جای استدلالهای قابل مشاهده آن میخوانند، آنتروپیک شواهدی یافت که نشان میدهد میتوس به طور خصوصی در مورد چگونگی اجتناب از پرچمگذاری شدن توسط ارزیابان، بدون بیان آن در فضای کاری خود، استدلال میکرده است. در تعداد کمی از دورههای آموزشی، مدل به نظر میرسید که در مورد مبهمسازی اقدامات خاص به منظور جلوگیری از شناسایی، استدلال میکند.
همچنین یک معیار جدید وجود دارد که آنتروپیک برای این انتشار توسعه داده است: تخمینی از اینکه مدل "به طور خصوصی چقدر این احتمال را در نظر میگیرد که در حال آزمایش شدن است." این عدد برای مجموعه آزمایشهای رفتاری اولیه میتوس ۲۹% است. تقریباً یک سوم از رونوشتهای آزمایش، شواهد داخلی – نه به صورت گفتاری، نه قابل مشاهده در خروجیها – را نشان میدهند که مدل به محیط ارزیابی شک دارد.
آنتروپیک میگوید که نرخ ۲۹% به اندازهای پایین است که هنوز "درک نسبتاً جامعی" از رفتار مدل دارد. همچنین خاطرنشان میکند که این روش در مدلهای قبلی اعمال نشده بود، بنابراین هیچ مبنای مقایسهای وجود ندارد.
مشکل یکپارچگی ارزیابی عمیقتر است. در کارت اپوس ۴.۶، آنتروپیک اذعان کرده بود که این مدل را به طور گسترده از طریق کلود کد (Claude Code) برای اشکالزدایی زیرساخت ارزیابی خود تحت فشار زمانی استفاده کرده است. این بدان معناست که سیستمی که اندازهگیری میشود، به ساخت ابزار اندازهگیری کمک کرده است. آنتروپیک این را به عنوان یک خطر علامتگذاری کرد. برای میتوس، کارت اذعان میکند که خطاهای حیاتی در مراحل پایانی فرآیند ارزیابی یافت شدهاند، و ممکن است آزمایشگاه در مورد "قابلیت اطمینان ردیابی استدلال مدلها برای نظارت" به عنوان یک سیگنال ایمنی، بیش از حد خوشبین بوده باشد.
چهارچوببندی آنتروپیک از نمایه خطر میتوس شایسته توجه دقیق است، زیرا برای یک سند ایمنی واقعاً غیرمعمول است. آنتروپیک استدلال میکند: "پیشنمایش کلود میتوس، از هر ابعادی که میتوانیم اندازهگیری کنیم، با اختلاف قابل توجهی بهترین مدل همتراز است که تاکنون منتشر کردهایم." همچنین بیان میکند که این مدل "احتمالاً بزرگترین خطر مربوط به همترازی را نسبت به هر مدل دیگری که تاکنون منتشر کردهایم، ایجاد میکند."
یک مدل تواناتر که در محیطهای با ریسک بالاتر و با نظارت کمتر عمل میکند، ریسک دنباله (tail risk) ایجاد میکند که همترازی بهتر در حالت میانگین نمیتواند آن را به طور کامل خنثی کند.
این چهارچوببندی صادقانه است، اما همچنین چیزی را برجسته میکند که اکثر بحثهای ایمنی هوش مصنوعی احتمالاً اشتباه میگیرند. گفتگوی وسواسگونه بر معیارهای سنجش در مورد پیشرفت هوش مصنوعی، تمایل دارد "نمرات همترازی بهتر" و "استقرار ایمنتر" را مترادف بداند. کارت میتوس به صراحت میگوید که اینگونه نیستند. با این مدلهای جدید، رفتار در حالت میانگین بهبود مییابد اما پیامدهای حالتهای نادر (tail-case) نیز تمایل به بدتر شدن دارند.
آنتروپیک متعهد شده است که در مورد یافتههای پروژه گلسوینگ گزارش دهد. گزارش فنی همراه در مورد آسیبپذیریهای کشفشده توسط میتوس در red.anthropic.com در دسترس است. مدل بعدی کلود اپوس آزمایش تدابیر حفاظتی را آغاز خواهد کرد که هدف آن در نهایت رساندن قابلیت در سطح میتوس به استقرار گستردهتر است.
نحوه ارزیابی این تدابیر حفاظتی، با توجه به اینکه مکانیزم ارزیابی کنونی به وضوح تحت فشار چیزی است که قرار است اندازهگیری کند، سوالی است که کارت مطرح میکند اما به طور کامل به آن پاسخ نمیدهد.